How Monad Works
Monad Foundation
@monad_dev (opens in new tab)- Published on
- · 19 min read
This is updated from the original posting on 2025-02-17.
Here's a very brief survey of the technology behind Monad! See the docs for a more in-depth discussion.
- Summary / network parameters
- Decentralization
- Node components
- Code
- Major improvements
- MonadBFT consensus
- RaptorCast
- Transaction lifecycle
- Leader election
- Staking
- Asynchronous execution
- Block stages
- Speculative execution
- Optimistic parallel execution
- JIT compilation
- MonadDb
- Bootstrapping a node (Statesync/Blocksync)
- Summary
- Further reading
Summary / network parameters
- Monad is EVM bytecode-compatible (you can redeploy bytecode without recompilation)
- Cancun fork (TSTORE, TLOAD, MCOPY) is supported
- RPC is compatible with geth; see RPC reference
- WebSockets are supported; see WebSocket reference
- Blocks are every 400 ms
- Finality of block
Noccurs at the proposal of blockN+2, i.e. finality is 800 ms
- Finality of block
- Block gas limit in testnet is 150 million gas
- i.e. gas rate is 375 million gas/s
- this will increase over time
- Max contract size is 128 kb (vs 24.5 kb in Ethereum)
- 150-200 validators participate in consensus
- For an executive summary of what to know before deploying, see Deployment Summary for Developers
Decentralization
- The north star of Monad is decentralization. We are introducing new software algorithms that make decentralized systems more powerful without relying on expensive hardware or geographic centralization.
- These algorithms deliver high performance with a relatively modest hardware footprint:
- 32 GB of RAM
- 2x 2 TB SSDs
- 300 Mbps of bandwidth for validators (100 Mbps for full nodes)
- a 16-core 4.5 GHz processor like the AMD Ryzen 7950X
- You can assemble this machine for about $1500
- These algorithms deliver high performance while maintaining a fully-globally-distributed validator set and stake weight distribution
Node components
- Monad node has 3 components:
monad-bft[consensus]monad-execution[execution + state]monad-rpc[handling user reads/writes]
- Network is 150-200 voting nodes (we'll call them "validators" for the rest of this doc)
- Non-voting full nodes listen to network traffic
- All nodes execute all transactions and have full state
Code
- The Monad client is written from scratch in C++ (execution) and rust (consensus)
- The consensus/RPC client is open source and available here:
monad-bft - The execution client is open source and available here:
monad
Major improvements
Monad introduces the following major improvements:
- MonadBFT for performant, tail-fork-resistant BFT consensus
- RaptorCast for efficient block transmission
- Asynchronous Execution for pipelining consensus and execution to raise the time budget for execution
- Optimistic Parallel Execution for efficient transaction execution
- JIT Compilation of frequently-used contracts to accelerate execution
- MonadDb for efficient state access
MonadBFT consensus
Monad uses MonadBFT for its consensus mechanism.
MonadBFT combines the following properties, which we'll state briefly and then explain more fully:
- pipelined consensus (enables low block times - 400 ms)
- resistance to tail forks
- linear communication complexity (enables a larger, more decentralized network)
- two-round finality
- one-round speculative finality (speculative, but very unlikely to revert)
Explaining more fully:
- MonadBFT has pipelined consensus, which leads to greater efficiency and shorter block times, because a block gets produced every round. In pipelined consensus, although blocks take multiple rounds to gather sufficient proof to achieve finality, every round has a new block entering the progression.
- MonadBFT is resilient to "tail forking", the biggest problem with previous pipelined consensus mechanisms.
- Tail-forking is best explained with an example. Suppose the next few leaders are Alice, Bob, and Charlie. In pipelined consensus, second-stage communication about Alice's block piggybacks on top of Bob's proposal for a new block.
- Historically, this meant that if Bob missed or mistimed his chance to produce a block, Alice's proposal would also not end up going through; it would be "tail-forked" out and the next validator would rewrite the history Alice was trying to propose.
- MonadBFT has tail-fork resistance because of a sophisticated fallback plan in the event of a missed round. Without getting into too many technical details: when a round is missed, the network collaborates to communicate enough information about what was previously seen to ensure that that Alice's original proposal ultimately gets restored.
- MonadBFT has linear communication complexity in the happy path (ordinary case). MonadBFT employs "one-to-many-to-one" or "fan out, fan in" communication patterns where a leader broadcasts (almost) directly to each validator, who send their votes directly to the next leader. This is important because algorithms with quadratic communication complexity are limited in the size of their validator set due to messaging overhead.
- MonadBFT has two-round finality. Since rounds are every 400 ms, this means finality occurs in 800 ms.
- MonadBFT has one-round speculative finality. In short, although technically two rounds are needed to achieve finalization, after one round has elapsed, the likelihood that a proposal will ultimately finalize is extremely high.
- This is again due to the fallback mechanism.
The diagram below shows the progression of a block to finality in the ordinary case. Each proposal includes a new payload (new list of transactions) plus a Quorum Certificate (QC) for the previous proposal, assembled by aggregating everyone's votes on the previous proposal. If the 3 scheduled next leaders are Alice, Bob, and Charlie, then Alice's proposal will be finalized after Charlie sends his own proposal.
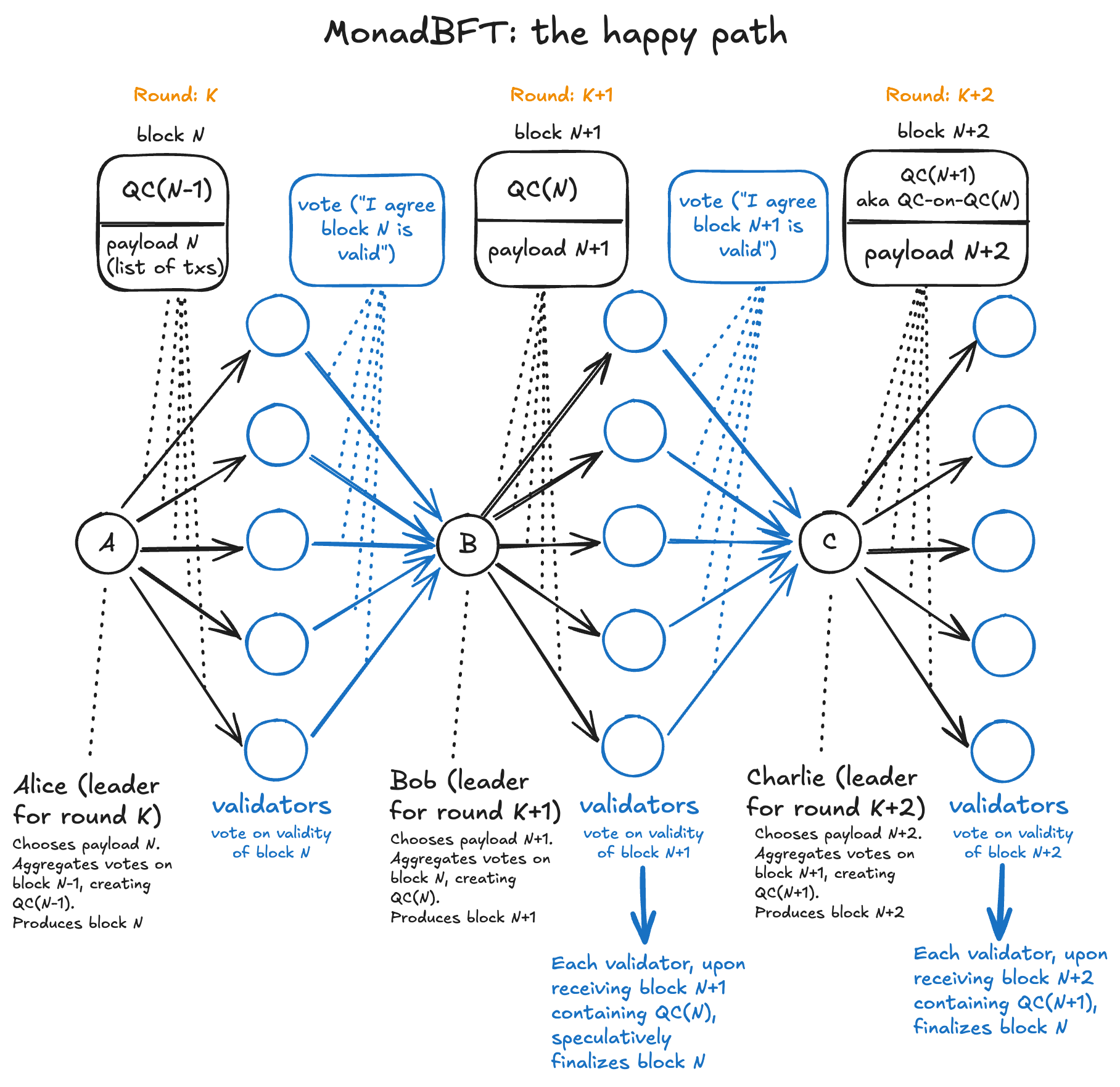
We've described the "what" but not the "how". To understand the fallback mechanism that defends all of these properties, see the MonadBFT docs or the MonadBFT paper.
RaptorCast
MonadBFT requires the leader to directly send blocks to every validator
However, blocks may be quite large: 10,000 transactions/s * 200 bytes/tx = 2MB/s.
- Sending directly to 200 validators would require 400 MB/s (3.2Gbps).
- We don't want validators to have to have such high upload bandwidth
RaptorCast is a specialized messaging protocol which solves this problem
In RaptorCast, a block is erasure-coded to produce a bunch of smaller chunks
- In erasure coding, the total size of all of the chunks is greater than the original data (by a multiplicative factor) but the original data can be restored using (almost) any combination of chunks whose total size matches the original data's size
- For example, a 1000 kb block erasure-coded with a multiplicative factor of 3 might produce 150 20kb chunks, but (roughly) any 50 of the chunks can reassemble the original message
- RaptorCast uses a variant of Raptor codes as the encoding mechanism
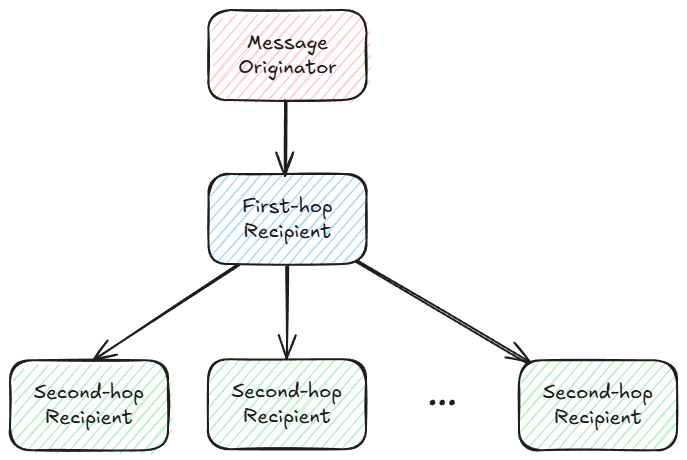
In RaptorCast, each chunk is sent to one validator who is tasked with sending the chunk to every other validator in the network
- That is, each chunk follows a two-level broadcast tree where the leader is the root, one other validator is at the first level, and all other validators are on the second level
- Validators are assigned chunks prorata to their stake weight
Here is the broadcast tree for one chunk:
- Thus, RaptorCast looks something like this:
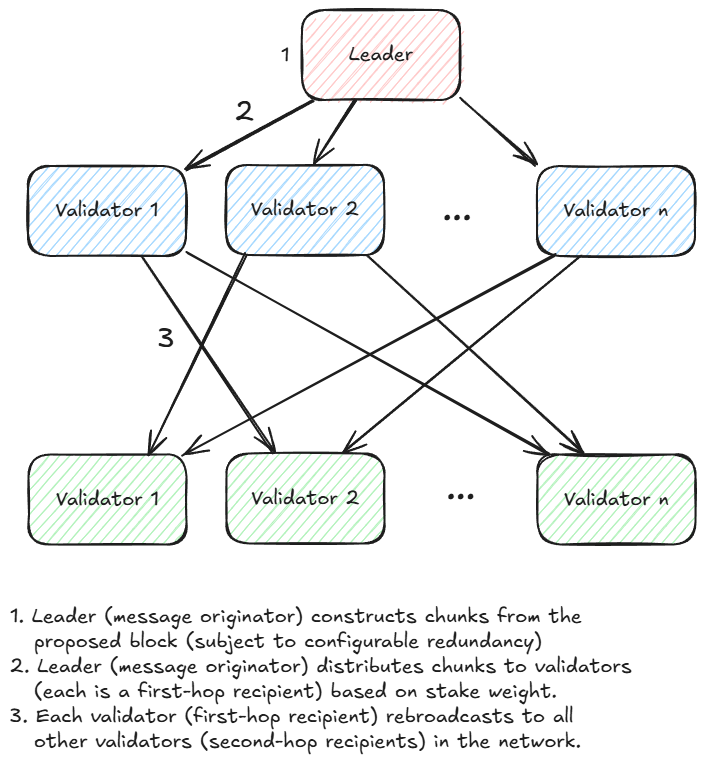
The RaptorCast protocol. Every validator serves as a first-hop recipient for a range of chunks, and broadcasts those chunks to every validator.
- Consequences:
- Using the two-level broadcast tree ensures that message delivery occurs within 2x the longest hop
- Upload bandwidth for the leader is limited to the block size times the replication factor (roughly 2)
- Since chunks are assigned pro-rata to stake weight, and BFT assumes no more than 33% of stake is malicious, at most 33% of chunks could fail to reach their recipients. With a replication factor of 2x, nodes can reconstruct the original block despite a maximum 33% loss.
Transaction lifecycle
- User submits pending transaction to RPC node
- RPC node sends pending transaction to next 3 leaders based on the leader schedule
- Pending transaction gets added to those leaders' local mempools
- Leader adds transaction to their block as they see fit [default: they order by descending fee-per-gas-unit, i.e. Priority Gas Auction]
- Leader proposes block, which is finalized through MonadBFT
Directly forwarding to upcoming leaders (as opposed to flood-forwarding to all nodes) greatly reduces traffic. Flood forwarding would take up the entire bandwidth, and is not suitable for a high-volume network like Monad.
Broader article: local mempool.
Leader election
- Leaders are chosen based on stake weight.
- An epoch occurs roughly every 5.5 hours (50,000 blocks x 0.4 seconds per block).
- Validator stake weights are locked in one epoch ahead (i.e. any changes for epoch
N+1must be registered prior to the start of epochN) - At the start of each epoch, each validator computes the leader schedule based on running a deterministic pseudorandom function on the stake weights. Since the function is deterministic, everyone arrives at the same leader schedule
Staking
- Stake is used to determine voting weights and block proposal rights.
- Staking secures the network by raising the cost of achieving a superminority (1/3) or supermajority (2/3) which would be needed in order to halt the network or enshrine an incorrect outcome, respectively.
- Delegation is supported
- The incentive to stake is to earn inflationary block rewards and priority fees
- Staking is done through a precompile which supports registering a new validator, delegating, undelegating, and choosing what to do with rewards (claim or compound)
- Validators must post a minimum stake themselves, and must achieve a minimum total stake to become a member of the active set.
- Validators may charge a commission of any rate between 0% and 100%
- Unstaking is subject to a withdrawal delay of 1 epoch (5.5 hours)
Asynchronous execution
Monad has asynchronous execution, also sometimes called deferred execution.
Consensus and execution are pipelined, with execution occurring in a staggered manner after consensus completes. This moves execution out of the hot path of consensus into a separate swim lane, allowing execution to utilize the full block time.
- During consensus, leaders and validators check transaction validity (valid signature; valid nonce; sender has sufficient balance to pay for the tranasaction), but are not required to execute the transactions prior to voting/proposing.
- After a block is finalized, it is executed; meanwhile consensus is already proceeding on subsequent blocks
Most blockchains have interleaved execution, which is less efficient because it significantly limits the time budget for execution.
- In interleaved execution, the execution budget is necessarily a small fraction of the block time because the leader must execute the transactions before proposing the block, and validators must execute before responding
- For a 400 ms block time, almost all of the time will be budgeted for multiple rounds of round-the-world communication, leaving only a small fraction of the time for execution
The below diagram contrasts interleaved execution with asynchronous execution. Blue rectangles correspond to time spent on execution while orange rectangles correspond to time spent on consensus.
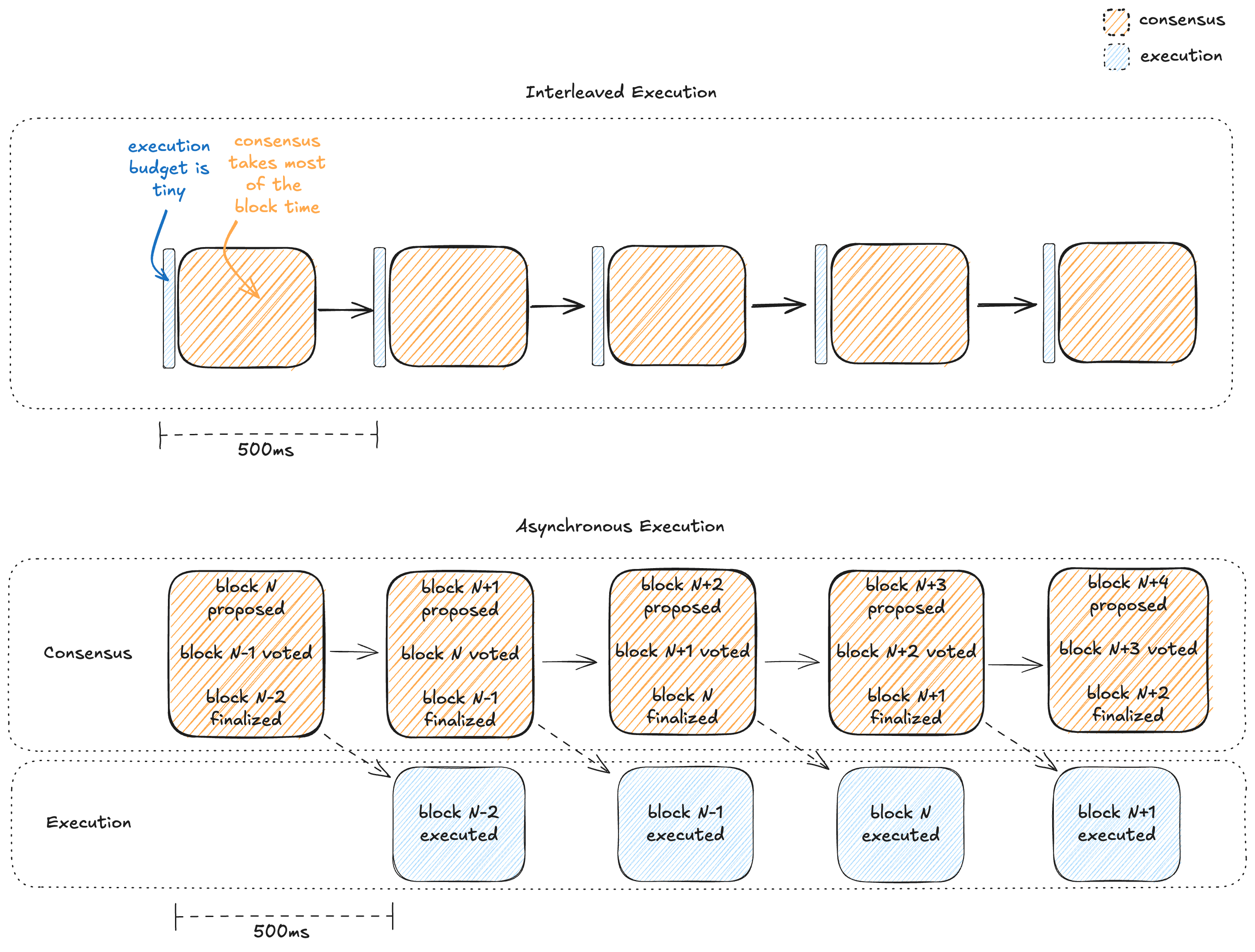
Interleaved Execution vs Asynchronous Execution.
The budget for execution is much larger in async execution.
Asynchronous execution is enabled by the reserve balance algorithm and state is authenticated using the delayed merkle root; these concepts are described next.
Full discussion: Asynchronous Execution
Delayed merkle root
From a protocol perspective, execution lags consensus by k=3 blocks. That is, when acting to come to consensus on block n, the consensus protocol assumes that nodes have access to the state trie at the end of executing block n-k.
(In practice, the nodes may have computed more recent blocks as well - but block n-k is like the "back edge of the belt" for a jogger on a treadmill; nodes absolutely must not lag by more than this or they will fall out of consensus.)
The block proposal for block n includes the merkle root of the state trie for block n-k. This delayed merkle root serves as a sanity check for each node to be sure that it didn't make a computation error when processing block n-k. If any node at any point discovers that their delayed merkle root does not match the rest of the network, they rewind to the end of block n-k-1 and re-execute block n-k.
Reserve balance
In consensus, due to asynchronous execution, the leader builds a block (and validators vote on it) without having access to the up-to-date state of the world. As mentioned before, the protocol only guarantees access to the k-lagged state.
This creates vulnerabilities. For example:
- Imagine that a leader who is building block 1000 receives a transaction from Xavier, and it looks like Xavier can pay for this transaction based on his balance from block 997.
- Say the leader adds the transaction to the block (and everyone votes to accept the block).
- Now, everyone executes block 998 and discovers that it included transactions where Xavier sent all of his balance out into other accounts.
- Now Xavier's transaction block 1000 is already locked in, consuming resources like blockspace, but when it is executed, the system won't be able to charge Xavier since all his funds were already transferred out.
This is a DOS vector that can be exploited to cheaply grief the network.
The Reserve Balance algorithm addresses this problem as follows:
- execution maintains balances for each account in realtime, as usual
- for each EOA account, a portion of funds (called the Reserve Balance, set to say
10 MON) is perpetually set aside to only pay for transaction gas fees (gas_bid * gas_limit) for transactions occurring in the nextk=3blocks - if at execution time, a transaction would reduce an accounts's balance below
10 MON(for example, due to swapping MON for a memecoin on a DEX), the transaction instead reverts. - at consensus time, the leader only builds (and validators only accept) blocks with transactions whose senders have less than
10 MONof inflight gas fees (i.e. gas fees spent between thek-lagged state and now)
In other words, execution carves out a small (but sizable considering it is only paying for gas) per-sender budget for gas fees in the next k=3 blocks. Consensus ensures that transactions getting pushed into the execution pipeline won't violate this budget for any sender.
Lastly, the Reserve Balance algorithm includes an exception for all senders being EOA accounts not currently delegated using EIP-7702: the first transaction (per sender) in the last k blocks is allowed to spend the balance below 10 MON. This is to improve UX, for example allowing someone to transfer all of the funds out. Since k=3 and the block time is 400 ms, for most users, most transactions actually fall into this exception.
A formal definition of the Reserve Balance is provided here, and you can find a good intuitive explainer (and a link to a Formal Verification of the algorithm's efficacy) here.
Gas limit is charged
As in Ethereum, users submit transactions with a gas limit, typically determined through simulation.
In Monad, users are charged based on the gas limit, i.e. there is no refund for using less gas at time of execution than specified. This is a consequence of asynchronous execution: the protocol needs to charge users for the gas limit they say they need, since leaders build blocks without knowledge of the outcome of execution.
Block stages
- Assume that a validator has just received block
N. We say that:- Block
Nis 'proposed' - Block
N-1is 'voted' - Block
N-2is 'finalized' - Block
N-2-kis 'verified' (because blockN-2, which has just been finalized, carries the merkle root for blockN-2-k)
- Block
- Note that unlike Ethereum, only one block at height N is proposed and voted on, avoiding retroactive block reorganization due to competing forks.
Speculative execution
- Although only block
N-2is 'finalized' and can definitively be executed, the execution system can still speculatively execute blocks as soon as it receives a block proposal. - Part of the reason speculative execution is safe is because MonadDB is a database of merkle trie diffs. Speculative execution produces a pointer to a new state trie, but in the event that a block ends up not being finalized, the pointer is simply discarded, undoing the execution
- Speculative execution also allows nodes to (likely) have the most up-to-date state, which helps users simulate transactions correctly
Optimistic parallel execution
- Like in Ethereum, blocks are linearly ordered, as are transactions. That means that the true state of the world is the state arrived at by executing all transactions one after another
- In Monad, transactions are executed optimistically in parallel to generate pending results for each transaction. A pending result contains a list of inputs (storage slots that were read (SLOADed)) and outputs (storage slots that were mutated (SSTOREd)) during the course of that execution.
- Pending results are committed serially, checking that each pending result's inputs are still valid, and re-executing if an input has been invalidated. This serial commitment ensures that the result is the same as if the transactions were executed serially
Example of optimistic parallel execution
Imagine that prior to the start of a block, the following are the USDC balances:
Alice: 1000 USDCBob: 0 USDCCharlie: 400 USD
(Note that each of these balances corresponds to 1 storage slot, since each is a value in the
balancesmapping in the USDC contract.)Two transactions appear as transaction 0 and 1 in the block:
- Transaction 0:
Alice -> Bob, 100 USDC - Transaction 1:
Alice -> Charlie, 100 USDC
- Transaction 0:
Optimistic parallel execution will produce two pending results (working in parallel):
PendingResult 0:
- Inputs:
Alice = 1000 USDC; Bob = 0 USDC - Outputs:
Alice = 900 USDC; Bob = 100 USDC
PendingResult 1:
- Inputs:
Alice = 1000 USDC; Charlie = 400 USDC(note Alice's balance of 1000!) - Outputs:
Alice = 900 USDC, Charlie = 500 USDC
- Inputs:
When we go to commit these pending results serially:
- PR 0 is committed successfully, changing the official state to
Alice = 900, Bob = 100, Charlie = 400 - PR 1 cannot be committed because now one of the inputs conflicts (Alice was assumed to have 1000, but actually has 900), so transaction 1 is re-executed
- PR 0 is committed successfully, changing the official state to
Upon re-execution of transaction 1:
- Inputs:
Alice = 900 USDC; Charlie = 400 USDC - Outputs:
Alice = 800 USDC; Charlie = 500 USDC
- Inputs:
This yields the final, correct balances:
Alice: 800 USDCBob: 100 USDCCharlie: 500 USDC
Observations:
- Note that in optimistic parallel execution, every transaction gets executed at most twice - once optimistically, and (at most) once when it is being committed
- Re-execution is typically cheap because storage slots are usually in cache. It is only when re-execution triggers a different codepath (requiring a different slot) that execution has to read a storage slot from SSD
JIT compilation
Most Ethereum clients execute smart contract code one instruction at a time, checking stack bounds and available gas before applying the instruction’s semantics. This is an interpreter. Interpreters are straightforward to build and maintain, have low startup latency, and can perform very well when implemented with modern techniques.
An alternative is to compile programs. Before execution begins, code is analyzed and transformed into a representation that executes more efficiently. Compilation adds upfront latency and complexity, but it happens once per contract version. If repeated executions are faster, overall system performance improves.
Monad features both a highly optimized interpreter and a bespoke native-code compiler. Execution tracks the most frequently-used contracts and compiles them asynchronously so that subsequent calls execute more efficiently. The compiler preserves exact EVM semantics, including gas calculations and error behavior.
For simplicity and portability, many compilers target a higher-level intermediate representation (e.g., LLVM IR or Cranelift). Because the Monad client targets a specific hardware configuration, the compiler emits native x86-64 directly to maximize control and performance while still matching EVM behavior exactly.
For additional details, see the docs.
MonadDb
- As in Ethereum, state is stored in a merkle trie. There is a custom database, MonadDb, which stores merkle trie data natively
- This differs from existing clients [which embed the merkle trie inside of a commodity database which itself uses a tree structure]
- MonadDb is a significant optimization because it:
- eliminates a level of indirection
- reduces the number of pages read from SSD in order to perform one lookup
- allows for async I/O, and
- bypasses the filesystem.
- State access [SLOAD and SSTORE] is the biggest bottleneck for execution, and MonadDb is a significant unlock for state access because it:
- reduces the number of iops to read or write one value,
- makes recomputing the merkle root a lot faster,
- it supports many parallel reads, which the parallel execution system can take advantage of.
Synergies between optimistic parallel execution and MonadDb
- Optimistic parallel execution can be thought of as surfacing many storage slot dependencies – all of the inputs and outputs of the pending results – in parallel and pulling them into the cache
- Even in the worst case where every pending result’s inputs are invalidated and the transaction has to be re-executed, optimistic parallel execution is still extremely useful by “running ahead” of the serial commitment and pulling many storage slots from SSD
- This makes optimistic parallel execution and MonadDb work really well together, because MonadDb provides fast asynchronous state lookups while optimistic parallel execution cues up many parallel reads from SSD
Bootstrapping a node (Statesync/Blocksync)
- High throughput means a long transaction history which makes replaying from genesis challenging
- Most node operators will prefer to initialize their nodes by copying over recent state from other nodes and only replaying the last mile. This is what statesync accomplishes
- In statesync, a synchronizing node (“client”) provides their current view’s version and a target version and asks other nodes (“servers”) to help it progress from the current view to the target version
- MonadDb has versioning on each node in the trie. Servers use this version information to identify which trie components need to be sent
- Nodes can also request blocks from their peers in a protocol called blocksync. This is used if a block is missed (not enough chunks arrived), as well as when executing the “last mile” after statesync completes (since more blocks will have come in since the start of statesync)
Summary
A high performance L1 requires harmonious optimization across the board, with many sub-optimizations including many not mentioned here. The result is a system with performance, decentralization, and compatibility.
Further reading
Read the docs or check out the code: