Monad Bugfinder: lessons from a month of AI-assisted bug hunting
Antonio Viggiano
@aviggiano (opens in new tab)- Published on
- · 20 min read
Introduction
Over the past month, the Monad Foundation security team has built and operated Monad Bugfinder, an internal AI-assisted vulnerability discovery and triage system targeting the Monad blockchain: the C++ execution client (monad) and the Rust consensus client (monad-bft).
The motivation for this work was to better understand LLM-assisted cybersecurity systems, their strengths and weaknesses, and build an evaluation baseline to compare our tool against external security providers.
By the end of the first month, the system had produced a number of quality findings, validation gates, and backtests against confirmed bug bounty submissions. More importantly, we derived a clearer picture of where this kind of automation actually pays off and how we see the initiative evolving going forward.
Why bother
AI as a new instrument in projects' security toolbelts
With recent improvements in LLMs, automated vulnerability research has earned a real place in the security framework of any organization, primarily due to its impact relative to price and speed. Even if these systems do not find all bugs, and even if they do not replace human security reviews, they often find more complex bugs than static analyzers at a fraction of the cost and time of a manual audit, including zero-days that have sat undiscovered in widely used software for decades. This means they are becoming another instrument that projects can apply to strengthen their systems, in addition to, and not as a replacement for, all the other methods they are already using.
Advances in agentic security are happening quickly, as the reliability of frontier models continues to improve in coding and in understanding. SWE-bench Verified scores jumped from roughly a third of real GitHub issues resolved in late 2024 to around 80% by early 2026 across all major frontier models. Defenders should arm themselves with similar tools as attackers to make sure they are providing the best security to their teams. This is no longer hypothetical: independent research is now showing that more than half of the blockchain exploits carried out in 2025 could have been executed autonomously by current AI agents, and broader industry coverage describes 2026 as the year of AI-assisted attacks.
To build or to buy?, that is the question
Many reputable audit companies and new AI-driven security vendors are appearing fast in this space, with scan prices that typically range from low-four to mid-five figures per engagement, and quality that varies a lot from one provider to another.
We wanted an internal system for two reasons: (1) to establish a baseline we could benchmark external providers against; and (2) to cover the gaps that providers typically do not focus on, such as cross-language boundaries, custom architecture that accounts for parallel execution, and specific validation requirements.
Monad is a useful target for this because of the separate but tightly coupled architecture. Although separate C++ and Rust clients exist, many checks are deferred from consensus to execution and vice versa, which is usually where most false positives or incorrect assumptions arise, and where traditional unit tests can fall apart.
System design
Design influences
When considering a design for such a system, we focused on simplicity rather than building something completely new from scratch. Our main focus was to ship something fast, even if not perfect, and iterate from the initial learnings.
Given that, we settled on a few initial designs, which, although simple, were able to supply all these needs.
Two pieces of prior art shaped the system.
The first is Anthropic's Mythos Preview write-up, where the headline result was that a fairly simple harness works surprisingly well:
- rank files 1–5 by likely bug density
- spin up parallel agents that each focus on a different file
- give agents a minimal prompt ("find a security vulnerability in this program"), let them iterate inside an isolated container
- run a second AI pass that asks "is this report real and interesting?"
The key design choice is minimal prompting plus agentic freedom to inspect, instrument, and test.
The second is TxRay, which proposes a structured, evidence-first approach to blockchain incident postmortems: decompose claims, generate competing hypotheses, run a skeptical "challenger" with veto power, and climb a reproduction ladder before issuing a verdict.
Mythos is good at generating leads. TxRay's shape is good at not believing them. We wanted both.
Architecture
The system has two separate services: a finder that generates leads and a triager that investigates each lead as an allegation, and tries to validate or reject it. Findings flow through a structured relational database as the single source of truth for auditability and for evaluation of subsequent runs.

This split may sound reasonable or obvious, but it was not how the system started. Since the two reference materials were not designed to talk to each other, the early design mixed discovery, root-cause analysis, reproduction, patch suggestions, and even variant mining in a single pipeline. As a result, too many failures occurred during the message-passing layer, which caused both time and inference tokens to be unnecessarily wasted. After a few days of testing, it became evident that we were mingling responsibilities in our harness, which prompted us to simplify the design.
Learning 1: cleanly separate discovery from validation from the start.
Finder
The finder runs in three stages: rank, hunt, persist.
Ranking
Before expensive hunter runs, the default structural ranker deterministically scores configured files, modules, and seams from 1-5 using a staged static-analysis pipeline. The bucket controls scheduling priority and eligibility: high buckets are selected first and low buckets can be skipped by min-score gates or cycle limits. The ranker also computes cost/confidence/hunt-budget metadata for downstream use, though runtime depth is still controlled by runner configuration.
The principle is that static structure, architecture knowledge, and historical change signals shape the search space before an agent starts reading code. We also cache ranker output keyed by git content identity, so that small changes do not necessarily redo the whole repo's execution, unless the operator chooses to.
Hunting
For each ranked target above some threshold (which is just a cost-benefit optimization), an agent runs inside an isolated container that already has the source tree, build tooling, and instrumentation available. The core prompt is intentionally minimal: basically the Mythos shape, with light adaptations.
On the hunting side, each agent can submit multiple findings per file. Although we parallelize across files, the dependency chain between files and functions may expose the same vulnerability across multiple files, so even if we run the system once per file, we can get the same bug instance dozens of times. This means a deduplication pass is also necessary at the triaging layer.
After the hunter has suggested a plausible vulnerability allegation, with enough evidence that deserve independent validation, it is promoted to a bug lead. More specifically, it should have some witness evidence, such as:
- sanitizer crash
- deterministic reproducer
- invariant violation
- state-root mismatch
- unexpected panic / abort
- replay mismatch after restart
- semantic mismatch against a spec
As we will soon learn, although this evidence would make for strong candidates, it is very easy to mistake a false positive for a valid bug with only a local POC.
This is where most bounty hunters stop, which is a mistake.
A working unit test is not a good enough argument for a true positive, confirmed finding. As per most bug bounty requirements, a full, E2E, no-assumptions POC must be provided.
Learning 2: only findings with E2E confirmation should be promoted.
Persist
Once a hunter promotes an allegation to a bug lead, the finder writes it to the relational database as an immutable row, along with all supporting witness evidence, metadata, and the state that produced it. Original leads are never mutated; instead, every downstream step (claims, validation, witnesses, verdicts) is appended on top, which gives us a full audit trail of how each lead evolved through the system.
This append-only model is what makes the database usable as the handoff point between finder and triager: the triager picks up leads by querying for new rows in a known state, without needing any direct coupling to the finder service. It also means we can replay or backtest historical leads against different triager logic.
Triager
Initial architecture
Earlier versions of the triager included a "variant analysis" step that suggested other instances of the same bug in the codebase. This was an unnecessary "hallucination generation" machine, because this component did not have the full list and context of the finder. As a result, it produced a stream of allegations that did not help with true-positive vs. false-positive adjudication.
Learning 3: Lead generation should not be executed during the triaging workflow. If a finding can be combined with another to produce a stronger vulnerability, this should be done as a separate step.
Another key change that we implemented was to move away from JSON files as a message passing mechanism, which came from the original TxRay paper. The downside of using loosely structured files for input that required strict validation was that sometimes the agents would omit certain fields and would produce properties that would not fall into the expected values. In addition, querying JSON through rg was unreliable and would sometimes fail because of the lack of file structure or querying capabilities.
Using a Postgres database is much better suited for persistent data storage since we could explicitly require enums or key type for all columns, which would be validated at insertion time. In addition, a centralized database also allowed us to scale horizontally in the number of finders and triagers since they would all read and write data into a single source of truth.
Learning 4: a relational database is a strong component in multi-agent harnesses, as enums and strict schemas can be used for validation, consistency and integrity
Finally, another change we implemented was to greatly simplify the number of internal specialized agents on the triager, from six to three. Early triager re-did work finder had already done: it would re-generate hypotheses, re-write PoCs, and sometimes invent new findings entirely. Reducing specialized agents that were simply redoing previous work from the finder meant a faster life cycle and fewer failed communication messages.
Learning 5: locking in a strict division of responsibilities and specialized agents can help reduce failed runs and improve the system's reliability
Current architecture
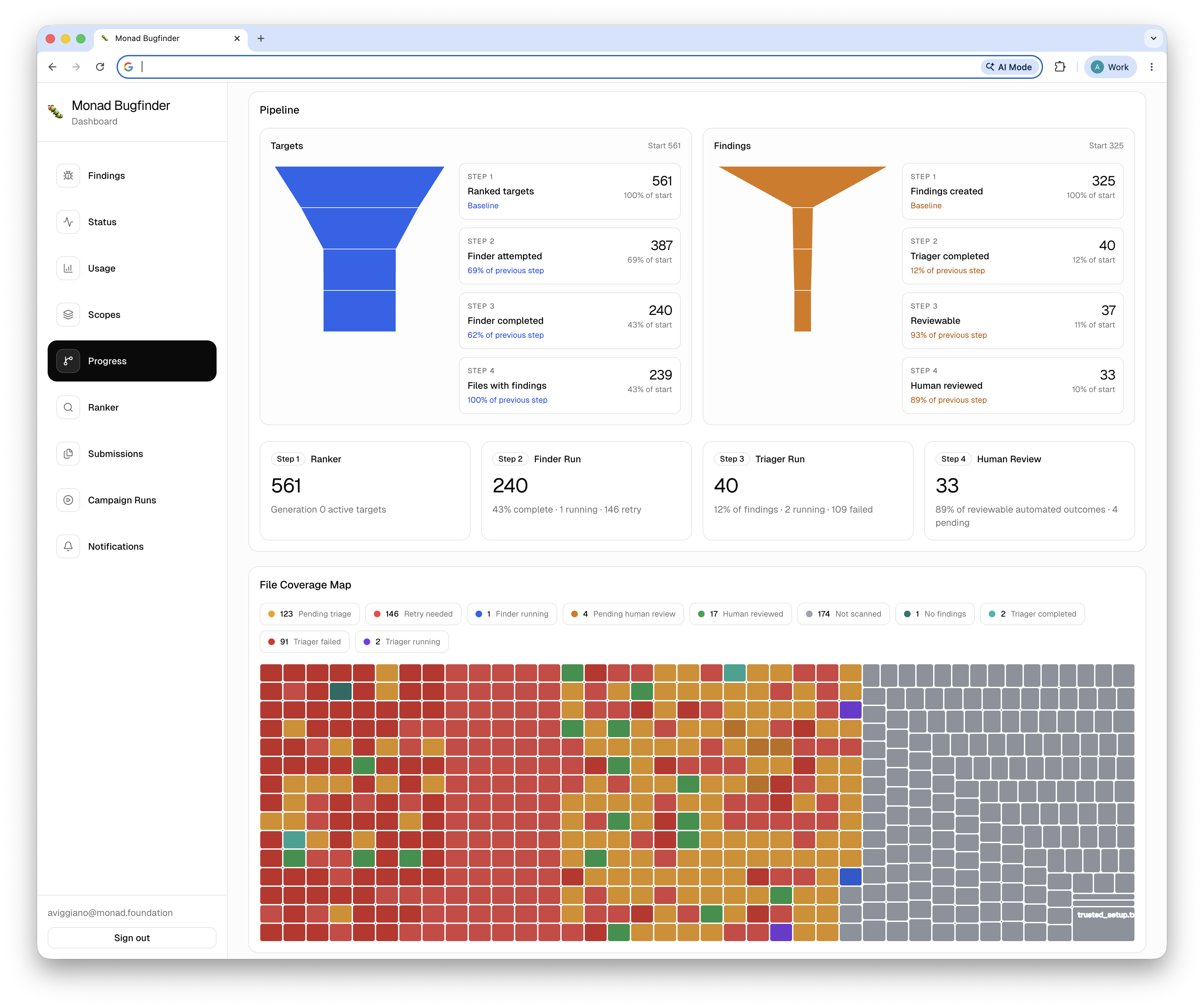
The current triager pipeline is best understood as three clean-context agentic phases wrapped around deterministic setup and persistence:
- verifier-first review
- agentic witness ladder
- final adjudication
Before any witness work, the triager normalizes the incoming case, collects deterministic evidence, discovers the execution environment, and then starts the verifier-first review.
Verifier-first review
This verifier treats the lead as an allegation: its job is to look for explanations that contradict or narrow the claim, produce a corrected lead framing, decompose the report into atomic claims, generate competing hypotheses, identify blocking unknowns, name the validation types the case requires, and decide whether runtime witness execution is materially needed.
This phase is where the triager deliberately resists being anchored by a confident report, which is the failure mode that defines most low-quality automated triaging systems: by construction, the default behavior of an LLM that is handed a bug is to agree with it, as it is simply predicting the next tokens from a given context. This means that, without adequate prompt engineering and POC validation, it will not be very good at adjudicating true positives from false positives.
Our very first triaging experiments confirmed exactly that: a one-line prompt asking the model to review a bug bounty report and decide whether it was a true positive or false positive ended with the model agreeing with the reporter most of the time, anchored by the confidence of the original write-up. Layering on more aggressive prompt engineering, instructing the model to push back, demand evidence, and propose alternative explanations, moved the needle but did not close the gap. Borderline cases still slipped through as incorrect confirmations, which is where the validation gates entered to help tighten precision.
Agentic Witness Ladder
If the verifier decides that runtime proof is needed, the triager starts a second kind of clean-context agentic work: the witness ladder. Internally, this ladder runs across escalating rungs:
module -> component -> boundary -> full-node -> cluster
Each rung receives the normalized report, prior witness attempts, environment-discovered runtime targets, and a witness-oracle plan. The agent decides how to investigate inside the rung.
A witness is meaningful only when a reproduction-oriented runtime action produces evidence and an oracle triggers on that evidence with enough artifacts persisted for a human to replay or audit the result. The very first version of the system counted "I successfully built the project" as evidence in the same bucket as "I reproduced the bug". The redesign separated environment discovery into its own artifact, kept helper/probe success out of witness proof, and made witness execution agentic-only.
Learning 6: environment discovery and witness execution must be separate artifacts. Counting compatibility checks as reproduction evidence will usually lead to false positives.
The ladder lets triager scale effort without expecting every report to need a full validator cluster setup. A module witness may be enough for a narrow local mechanism, which could be ground for an Informational-severity finding. A full-node witness is needed when the claim depends on a real node entry point, typically for Medium-severity findings and above. A cluster-level witness is expected for distributed, consensus, liveness, fork, proposer, validator-composition, or schedule-sensitive claims.
Final Adjudication
After witness execution, the triager starts a final agentic pass: adjudication. This adjudicator sees the claim ledger, hypotheses, verifier review, challenger output, witness attempts, oracle results, runtime evidence summary, and runtime validation policy.
The key design choice is that final adjudication does not collapse everything into one confidence number. It separates mechanism, impact, runtime reproduction, public-entry proof, adversarial reachability, intended behavior, witness level, and terminal state.
That can be useful for future re-assessments. Many findings have a real mechanism but no proven impact, or reachable behavior with no security consequence. Keeping those dimensions separate prevents overclaiming.
The terminal states are triaged, false-positive, undetermined, and intended-behavior. The last one is useful when reports reproduce real behavior that matches official documentation or bounty rules.
After adjudication, the triager writes the final report bundle: final report, verdict package, claim ledger, execution trace, triager summary, and reproduction package. For shared finder/triager validation, the relational database remains the canonical state; the bundle is the readable artifact humans use to audit what was claimed, what was tried, what reproduced, and why the terminal state was assigned.
Validation gates
The single highest-precision improvement we made, in the whole system, was introducing validation gates: hard requirements on what kind of proof a class of claim needs before it can leave the undetermined state.
For consensus-class findings (proposer abuse, quorum manipulation, stale rounds, signature or auth issues, etc.), we require a mock-swarm or monad-solonet-style reproduction: a small local cluster scenario with controllable validators. Anything that cannot demonstrate the behavior in those systems stays undetermined, regardless of how good the source-level reasoning looks. In practice, this gate has been worth roughly 100% precision on the consensus findings that pass through it. This led us to adjust the Bug Bounty submission guidelines to instruct security researchers to use those tools in their findings.
For execution-class findings, we lean on differential tests and the public EVM spec test suites. Many candidate bugs in EVM-adjacent code reduce to whether the implementation is different from the spec under a certain input, which is a good initial oracle to confirm or disprove a claim. Testing against the evmone or go-ethereum consensus clients helped us trim out some false positives and confirm true positives, mostly related to old fork versions where the implementation would not adhere to spec, without production impact.
Learning 7: strict validation gates is a strong pass to improve report quality and reduce false positives
We also run dual-provider validation: a finding is independently validated by a pair of frontier reasoning models, Codex and Claude Code, where disagreement defaults to undetermined. This made automated validation more conservative and favored precision over recall, which is the right tradeoff for our system.
Closing thoughts
The funnel after a month of operation looks roughly like this: for every reported finding, there are 10 confirmed issues, and for every confirmed issue, there are 10 bug leads.
This means each step drops the number of leads by about 10x before they cost human attention. That 100:10:1 ratio is the result of tuning the process for low reviewer load rather than high recall, to accommodate the volume of submissions the Category Labs development team receives. Moreover, even though the system is producing a number of valid, confirmed bugs, they may be local defects and not always reachable in production. In many cases, even if they can be triggered on mainnet, they do not have meaningful impact. Only one-tenth of confirmed issues become actual reports.
In the current architecture, each confirmed issue costs roughly $100 in API credits or, conversely, each reported finding costs roughly $1k. These are not the cost of the specific run that found a given bug, which we consider a vanity metric given the probabilistic nature of the system. Instead, this cost reflects the total spend divided by the number of confirmed issues or reported findings.
This number can be significantly lower than the cost per bug in a time-boxed security review (setting the cost per severity aside), or average bug bounty payouts per same severity type, and orders of magnitude lower than the impact of a single production incident.
The unit economics of vulnerability research are shifting, and any project that does not have an internal harness running continuously against its codebase is leaving a lot of value on the table.
The key takeaway is that AI does not replace human reviewers, but it changes which bugs security researchers can afford to look for. A bug class that was previously left open to the next audit cycle, or simply ignored due to scoping constraints, is now being continuously scanned 24/7. That is a structural shift that supports building an internal solution even when excellent external partners exist.
Limitations and next steps
The system is incipient and purposefully simple, and we already have a big list of known issues, limitations, and room for improvement.
Evaluation framework
The biggest gap is the lack of a formal evaluation framework. We have been improving the system iteratively, from a one-liner triage prompt, to a structured prompt, to a TxRay-inspired flow, to the current shape, and we have noticed it getting better at each step, but we cannot quantify that precisely. The next major piece of work is building an evaluation corpus from historical and current reports, so we can make bigger changes more confidently.
Harness optimization
Another big improvement is harness optimization in the spirit of AgentFlow: for a fixed model, prompt/tool/sub-agent/graph changes can produce large quality jumps. Using the paper's definition, Monad Bugfinder currently has a pre-defined number of specialized agents, with fixed topology, fixed prompt, and fixed tools. According to the paper, each one of these variables can and should be fine-tuned to improve performance.
Thinking from first principles, as well as from the results of our internal findings, we know that the severity produced by our system is currently capped. The Mythos-style harness is excellent at breadth, surfacing a lot of plausible candidates, but it is not yet producing the kind of impactful findings that the Anthropic write-up describes. We believe this is related to the models being used, as previous research has already demonstrated how upgrading the model number can directly impact the system output, while AgentFlow showed that changing the architecture has the same effect.
This means improvements in the harness are our biggest leverage in quality.
Lots of TODOs are in our roadmap: free-form shell can be optimized by using purpose-built tools; specialized agents can be better instructed with previous threat modeling; orchestration can be better configured with different topologies and parallelization; file-based scanning can be complemented with module-focused reviews; individual bugs can be combined to produce higher-severity findings; undefined-behavior issues without proven reachability can be targeted with tailor-made fuzz harnesses; etc.
Cost-performance optimization
For the first version of Monad Bugfinder, we have not optimized for cost-performance: today we default to the maximum reasoning effort from frontier models from OpenAI and Anthropic for everything, and it is not obvious which stages need that and which would do fine on cheaper ones. Moreover, newer research labs have been emerging with very good benchmarks and different architectures, which we would like to integrate and extend in the near future.
Reducing the work of the human triager
Triage is currently our biggest bottleneck. We are generating more findings than we can review by hand, and a few of the issues that external researchers reported were findings our system likely would have triaged eventually but had not gotten to. This means humans are already DoS'd by bug leads, and scaling this is not just an infrastructure problem, but a cost and time allocation problem.
We believe achieving a stage where human triaging is greatly reduced is completely feasible within the next few months. With the advent of Codex's /goal command, we were already able to simplify most of the manual work in a human review of a triaged lead, thereby reducing the number of hours spent by a human in confirming a bug is valid. This also suggests that the triager harness may be further simplified just because of stronger tooling in the base models.
Improving the validation gates
Our validation diversity is important but still thin: a few consensus and execution oracles exist, but adding a stricter “bug type to reliable validation method” mapping would greatly benefit the adjudication mechanism.
Iterate, iterate, iterate
The honest reading is that a lot of the scaffolding we built this month may no longer be relevant in the next one. Most, if not all, of fine-tuning exists only to compensate for limitations that the next generation of models may not have.
Improvements in context size can make up for a lot of optimizations with specialized agents and tools. Specific threat modeling and prompting can also be made obsolete by models with more training parameters and higher reasoning effort. This is why being able to learn fast and iterate is paramount in defensive security.
If you're working on something similar and would like to share challenges, learnings, and suggestions, please reach out. We would love to hear from you.