Understanding LOBSTER: A gas-efficient Onchain Order Book Mechanism
michaellwy
@michael_lwy (opens in new tab)- Published on
- · 11 min read
Have thoughts on this topic? Join the conversation on X.
Introduction
Building a scalable order book on the EVM was once nearly impossible. Ethereum mainnet’s 12-second block times and exorbitant gas fees made it impractical for order book exchanges, which demand ultra-low latency and heavy computational throughput.
EVM-compatible L1s such as Monad have largely addressed the limitations on the latency front. With parallel execution, asynchronous execution and a fast consensus mechanism MonadBFT, Monad supports 500ms block time and finality within a second. This sets a solid foundation for order book exchanges to emerge on EVM.
Another challenge with onchain order books is gas cost. While gas fees on Monad are already orders of magnitude lower than on Ethereum, posting and cancelling thousands of orders per second through smart contracts is still gas-intensive. This makes optimizing the structure of the order book itself critically important.
Clober, a fully on-chain order book DEX built on Monad, introduces LOBSTER (Limit Order Book with Segment Tree for Efficient oRder-matching), a mechanism that leverages thoughtful data structures designed to address gas-related challenges.
- The two challenges of order book on EVM
- Challenge 1: Efficiently Settling Orders without Iteration
- Challenge 2: Avoiding Expensive Scans Across Sparse Price Levels
- Conclusion
The two challenges of order book on EVM
Implementing a scalable order book on EVM is non-trivial. Unlike CEXs, which can freely iterate through large order queues in off-chain memory, smart contracts face the unique constraint of gas fee. This brings out two challenges:
- Iterating over orders to settle trades: When a trade happens, one taker order (market order) might match with many existing maker orders (limit orders). On a CEX, the engine would loop through possibly hundreds of orders to distribute the trade outcome (fill multiple orders). Onchain, looping through a list of makers in a single transaction is gas intensive. The challenge is how to settle trades (i.e. pay each party the correct amount) without iterating over every filled order in one go.
- Iterating over price points for large orders: In an order book, a large market order might consume liquidity across multiple price levels. For example, if you buy a large amount, you might buy everything at the best price, then move to the next price, and so on. If many price levels in between have no orders, meaning there’s a gap, a naive implementation would have to scan through all possible prices in that range to find the next available orders. Again, extremely gas inefficient.
These problems forced some onchain order book attempts to sometimes make compromises such as limiting the number of orders in a queue or relying on off-chain matching.
Clober introduces LOBSTER, which stands for Limit Order Book with Segment Tree for Efficient oRder-matching. It is a mechanism that seeks to tackle these challenges and enable fully onchain limit and market orders on EVM at a manageable gas cost.
Challenge 1: Efficiently Settling Orders without Iteration
An order book is just a queue of offers. Let’s consider the example of 3 people trying to sell 10 MON at the same price:
- Alice: wants to sell 10 ETH
- Bob: also wants to sell 10 ETH
- Carol: same, 10 ETH
They’re placed into a queue, ordered by who arrived first. Now, a buyer Dave comes in. Dave wants to buy 15 ETH at that price. So what happens? First, he buys 10 ETH from Alice (her order is fully filled). Then he buys 5 ETH from Bob (order is partially filled). Carol’s order stays untouched.
This is called matching: one buyer (a taker) is matched against one or more sellers (makers), starting from the front of the line. On EVM, that “loop through every seller” step could cost a lot of gas, especially if the queue is long (imagine 500 people with small orders).
LOBSTER’s idea is to remove the burden of immediately paying all makers. Instead, after the trade, the taker’s transaction will record how much of each order has been filled (and hold those funds in the contract), but not actually loop through and send funds to each maker. Each maker can later call the contract to claim whatever portion of their order was filled. This way the expensive looping is avoided in the initial trade.
Practically, LOBSTER does this through something called claim range. Imagine all the orders at a given price are lined up in a queue (ordered by time). Recall our example: Alice placed the first order (10 ETH), Bob the second (10 ETH), Carol the third (10 ETH).
Initially, none are filled, so all are unclaimed. We can assign each order a range based on the cumulative size of orders before it:
- Alice’s order covers range [0, 10] (meaning if up to 10 ETH is traded, that would fill Alice’s order fully).
- Bob’s order covers [10, 20] (it starts at 10 because Alice’s 10 must fill first, and goes to 20 if Bob’s full 10 ETH would be filled).
- Carol’s order covers [20, 30].
Claim Range Visualizer
Now, we define T = total claimable amount, which is the total volume taken from this queue so far (i.e. how much ETH has been bought from these orders but not yet claimed by makers).
If a taker bought 15 ETH from this price level, then T = 15. Alice’s range [0,10] is fully covered (T=15 > 10) so Alice can claim all 10 ETH she wanted to sell. Bob’s range [10,20] is partially covered (T=15 is between 10 and 20), so Bob can claim 5 ETH out of his 10 (the remaining 5 ETH of Bob’s order is still unfilled). Carol’s [20,30] hasn’t started filling (15 < 20) so Carol waits.
If Bob later cancels the rest of his order or claims it, Carol’s range would shift down accordingly. The key point is: given the total filled amount T, and knowing each order’s range, we can calculate how much that order can claim, without stepping through all orders individually.
There’s still one challenge: as orders are filled or cancelled, the total filled amount (T) changes, which means each order’s position in the queue (its range) needs to be updated. To do this efficiently, we need to keep track of the running totals of all order sizes.
To solve this, LOBSTER uses a segment tree, which is a data structure that enables fast calculation of range sums and efficiently updates when a single order changes. Instead of scanning every order in the list, the tree stores partial sums. This keeps performance scalable even as the number of orders grows.
Let’s look at an example. Consider this array:
- Index: 0 1 2 3 4
- Array: [2, 1, 5, 3, 4]
Each number in the array is the size of an order in a queue (e.g., Alice wants to sell 2 ETH, Bob 1 ETH, Carol 5 ETH etc.). In the segment tree structure, this data can be visualized to be something like the below:
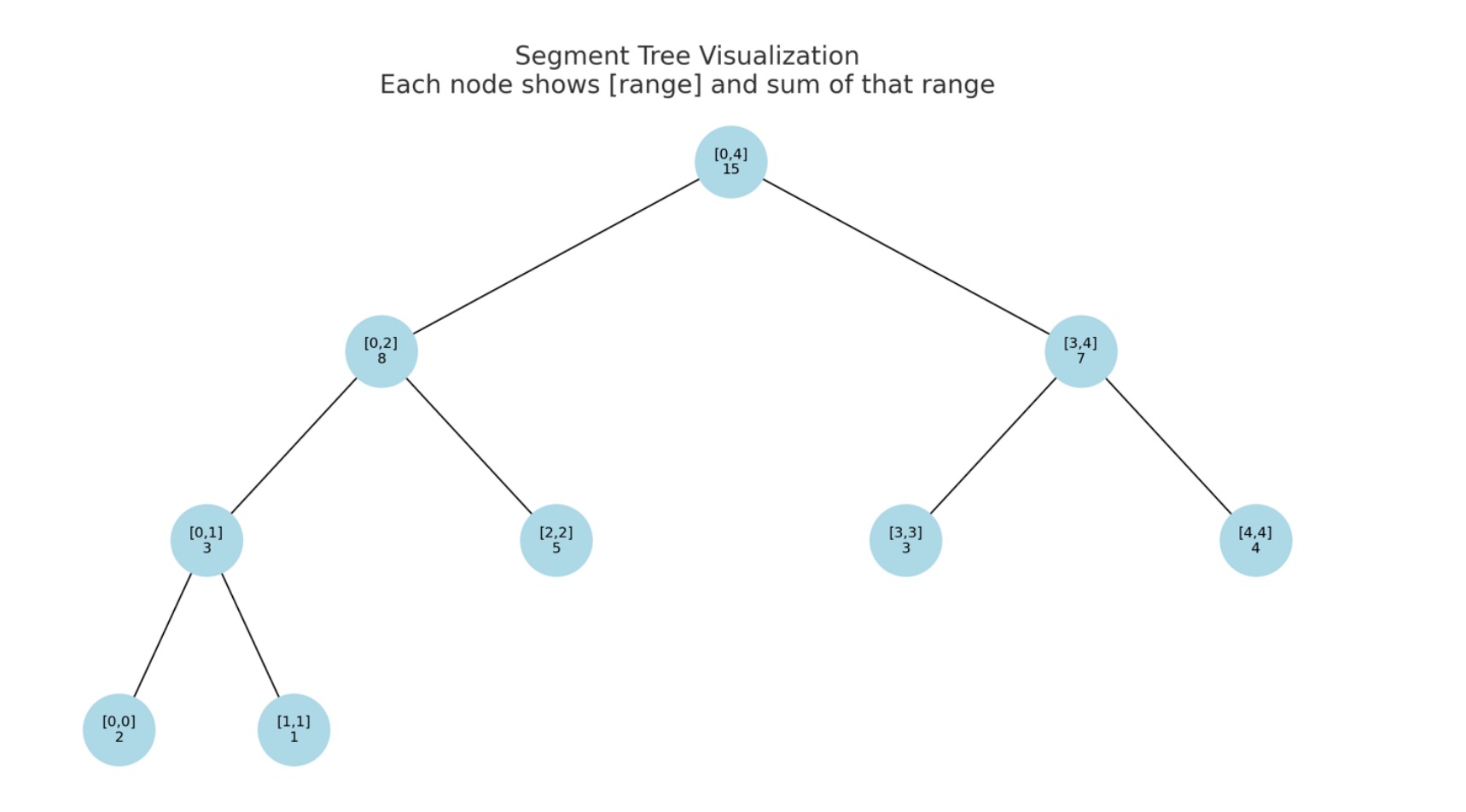
The root node (at the top) covers the whole array: it basically mean sum(0–4) = 2+1+5+3+4 = 15
A segment tree recursively splits the array into halves: Root node represents the entire range, e.g., [0–4] It splits into two children:
- Left child: first half → [0–2]
- Right child: second half → [3–4]
This split continues recursively:
- [0–2] → [0–1] and [2–2]
- [3–4] → [3–3] and [4–4]
Well what’s the point of this? Imagine you want to know how much of the order book is filled up to Bob (i.e., index 1). Instead of summing from 0 to 1 manually, the segment tree lets you jump to pre-computed partial sums.
To get the total of a subrange like [1–3], you don’t need to add up one-by-one. Instead you traverse the tree and combine pre-computed sums from child nodes that fully or partially cover [1–3]. If one element changes (e.g., a partial fill on Bob’s order), only the nodes along the path from that leaf to the root need to be updated.
That’s the basic concept of segment tree, which is cleverly utilized to avoid costly computation to streamline order book performance on EVM. Clober’s design takes this further and uses what they call Segmented Segment Tree, which you can explore further here.
Challenge 2: Avoiding Expensive Scans Across Sparse Price Levels
In an order book, prices aren’t continuous. There can be big gaps between the price levels that actually have orders.
For example, if sell orders exist only at $1000 and $2000, and you place a large market buy, the contract needs to “jump” from $1000 to $2000 to keep filling.
But onchain, prices are usually stored as a list of ticks (e.g. every $1). Naively, the contract would have to scan every tick between $1000 and $2000 (potentially 1000 steps) to find the next price with liquidity.
To avoid scanning through thousands of price levels, LOBSTER keeps track of only the prices that actually have orders. It does this using a data structure called a heap.
A heap is another tree-based data structure, but instead it is optimized for quickly retrieving the minimum or maximum element. It doesn’t maintain a full sorted list, but it guarantees that the top element is always the smallest (in a min-heap) or largest (in a max-heap). Notice in the illustration that the root node in min-heap is always the minimum value in that array and vice versa for max heap.
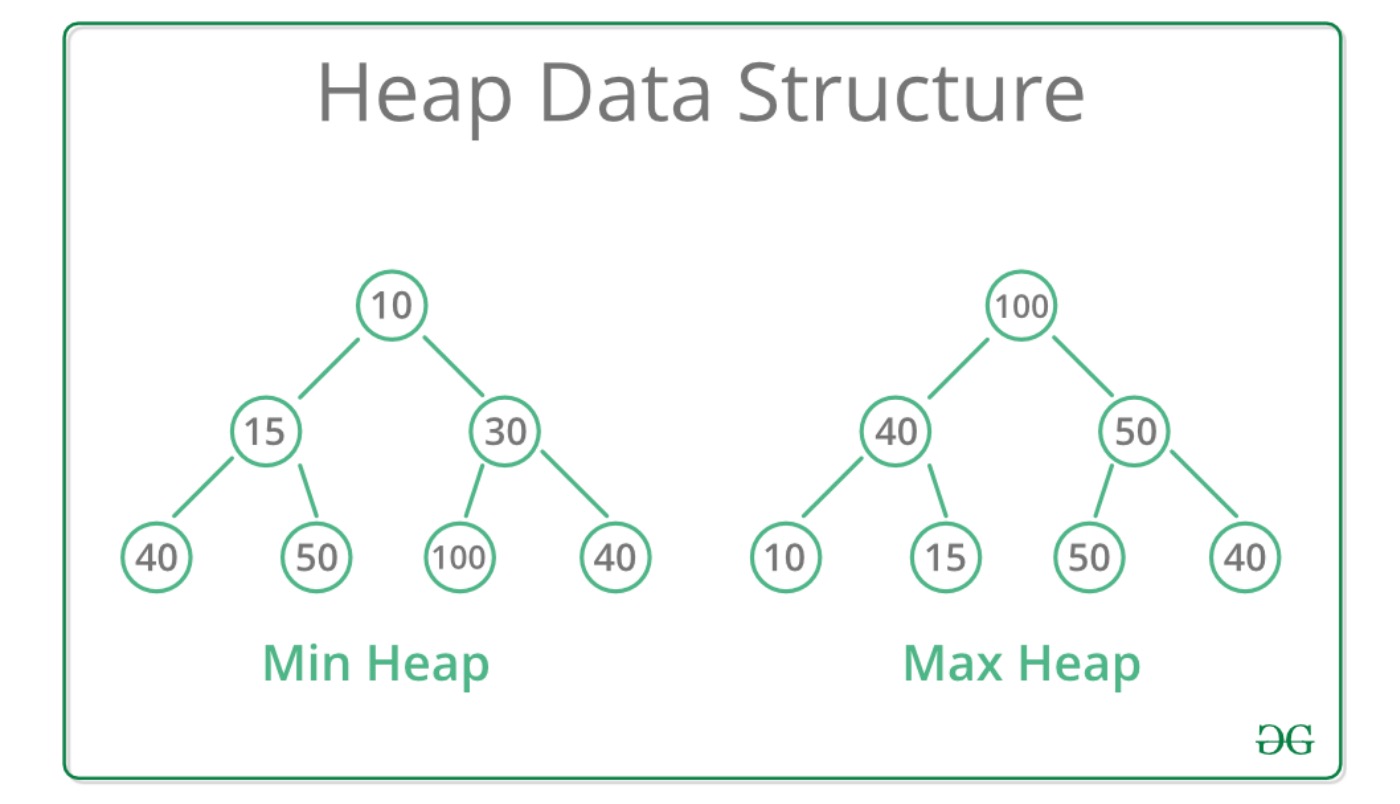
LOBSTER maintains two heaps:
- A max-heap for bids, so the contract can quickly access the highest bid price
- A min-heap for asks, so it can fetch the lowest ask price
Each time an order is placed at a new price level, that price is added to the appropriate heap. When the last order at a given price is fully filled or cancelled, that price is removed from the heap.
Let’s walk through an example:
When someone places a new order at a price level, say, a sell order at $1140. LOBSTER adds $1140 to this heap data structure. This heap acts like a live list of only the price levels that currently have open orders. If all orders at that price are later filled or cancelled, the price is removed from the heap.
This means the heap always contains a minimal, up-to-date index of “active” price levels. Inactive prices are never stored or checked.
Here’s why that matters. If you submit a large market buy that needs to consume liquidity at $1100, $1140, and $1200. Without a heap, the contract might have to loop through every price tick in between ($1101, $1102, ......, $1199) just to figure out if any of those prices have orders.
With the heap, this loop is avoided. The contract can simply ask the heap for the next valid price with liquidity. This operation takes logarithmic time. It means that if there are n prices in the heap, the number of steps needed to find or update a price is proportional to log(n). For example, if there are 1,000 active price levels, it might only take around 10 steps to find the next best one. This is much faster than scanning all 1,000 levels directly.
A standard heap still requires multiple storage reads and writes for each insert or delete. So LOBSTER introduces the Octopus Heap, a custom, more gas-efficient version. Instead of tracking every price in full detail, Octopus Heap splits prices into two parts: a rough price range (the “region”) and the exact price tick within that range. This means that:
- A small heap tracks which regions currently have any orders (this is the “head” of the octopus).
- A compact map inside each region tracks which exact prices have orders (these are the “arms”).
In the illustration below, Each box (or “arms”) represents 256 fine-grained price ticks within that region. The ▓ marks show which specific price levels have active orders.
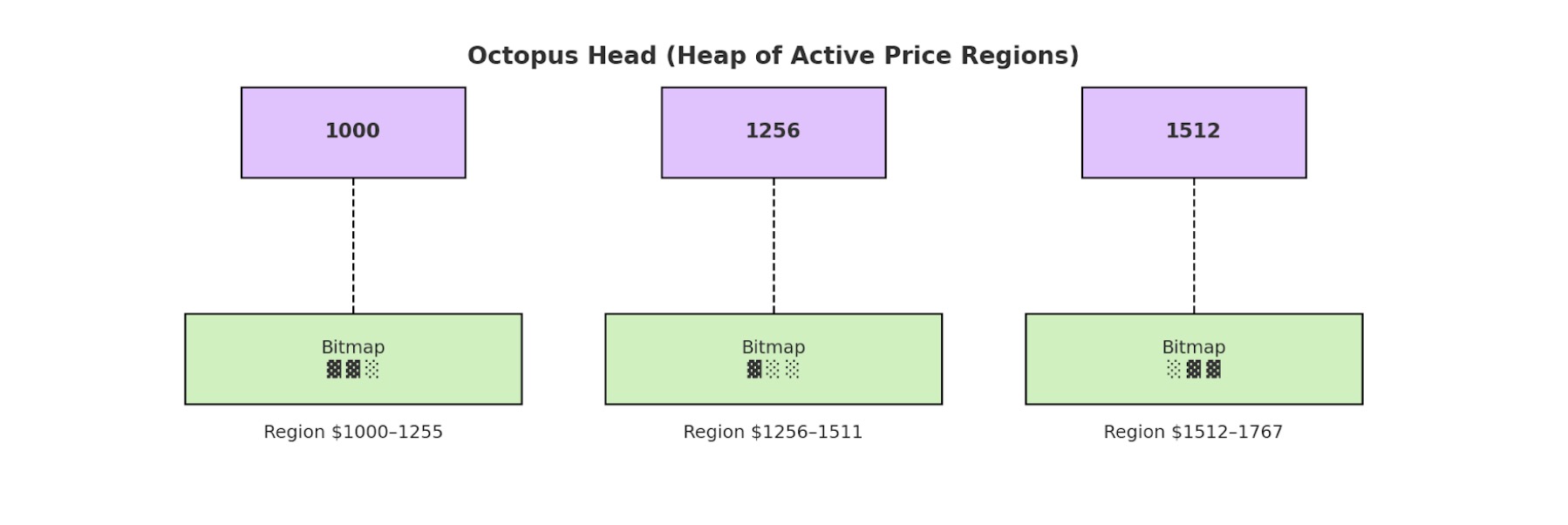
So when a trade needs to find the next price level it first looks inside the current region to see if there's another price with orders. If not, it moves to the next active region using the heap.
Conclusion
Clober’s LOBSTER mechanism is a compelling demonstration of what’s possible when you rethink the order book design from first principles. By blending classic data structures like segment trees and heaps with gas-aware engineering tailored to the EVM, it narrows the efficiency gap between onchain order books and AMMs.
That matters not just for performance but because order books unlock features AMMs can’t: granular control over execution, better pricing for large trades, and a foundation for more sophisticated market designs. In a space crowded with experiments, LOBSTER carves out a serious contender.