Ultrafuzz: end-to-end agentic fuzzing for Solidity smart contracts
Antonio Viggiano
@aviggiano (opens in new tab)- Published on
- · 18 min read
Introduction
Over the past weeks, the Monad Foundation security team has engaged with a few ecosystem projects to implement Ultrafuzz: an agentic orchestrator for Solidity smart contract fuzzing.
By the end of the engagement, Ultrafuzz had uncovered 27 distinct issues in the pilot protocol, ranging from Low to High severity. This was more than twice the number identified by any single other AI auditing solution we evaluated, and most of the findings were previously unknown despite the protocol having undergone multiple open-source and commercial AI security scans.
Ultrafuzz works by configuring a target repository with pre-built prompts and running those prompts through a cluster of agents that automatically enumerate system properties, implement fuzz tests and invariant tests, deduplicate and triage findings, and generate a final report for review. All of this runs through a single command.
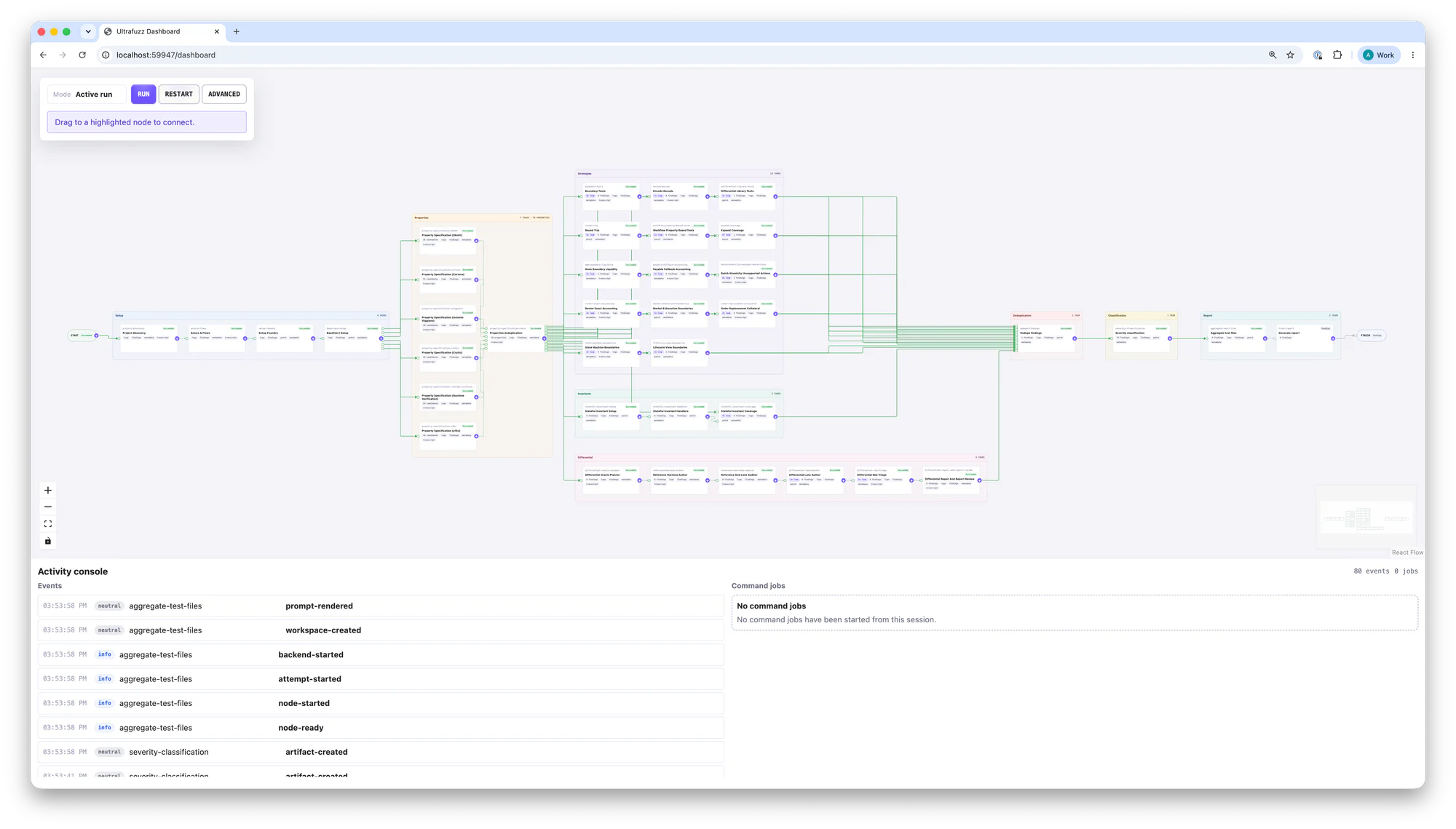
This tool builds on open-source frameworks and property specification guidelines, while adding an orchestration layer around the workflow that fuzzing specialists typically implement during engagements. Each step is assigned to an agent through a directed graph that can be extended and modified by users. The project draws on key learnings from Monad Bugfinder, our internal AI-assisted vulnerability discovery system for the Monad blockchain, by implementing some of the best practices we discovered while building that system.
Motivation
Ultrafuzz was born from an audit-readiness support program with an ecosystem project, where our security team paired with the project's developers to improve documentation and tests before an upcoming external security review.
Due to tight time constraints, all test code was generated by AI, with our team carefully designing the strategy, steps, and prompts. After understanding which key areas had the least coverage, and which testing methodologies could be applied to target specific weaknesses, in less than a week the project was extended to support stateless fuzz tests as well as stateful invariant tests. For reference, a typical fuzzing engagement can take 4-8 weeks, depending on the size of the codebase, which means this rapid effort was by no means sufficient or indicative of a thorough exercise. Still, it was a useful attempt to catch low-hanging issues when time and cost are the biggest bottlenecks, similarly to other automated tools.
We believe the key reason novel issues were found when prior AI audit tools missed them is that most implementations are currently focused on replicating the manual workflows that security researchers use. They start with threat modeling, then enumerate different specialized agents for each bug type, then hunt for issues and combine bugs to escalate the severity of a finding. This has been proven to work really well, and we encourage all projects to keep using these solutions to their advantage. The problem is that most, if not all, off-the-shelf solutions still lack fuzzing as a core component. As it has been shown, fuzzing will typically find different types of bugs than a manual review, which is why applying both techniques can be very powerful.
We present Ultrafuzz as yet another tool that projects can use alongside AI scans, so that they can combine these approaches. After Ultrafuzz is open sourced, we expect AI scanners to incorporate some of these strategies in their workflows and further expand their capabilities.
After this assessment, we asked ourselves: how can we scale this effort across Monad projects and the broader crypto ecosystem? This kickstarted the design discussion behind Ultrafuzz.
Development
Phase 1: Skills
After the initial success from the manual engagement, we began encoding each step we had conducted into the "modern way" of distributing software: skills.
Through a master skill and several specialized ones referenced by the primary skill, similar to other repositories, we hoped it would be possible to package our workflow as a one-shot prompt to the agent:
- Set up Foundry
- Understand the protocol's actors and user flows
- Create specific fuzz tests according to different strategies
- Deduplicate, triage, and report findings
This list of skills was encoded into a GitHub project that did not get far.
The core problem is that these skills ended too early, produced very few tests, and ultimately reported zero failing tests. For comparison, a fresh run of the "master" skill would produce only 50 fuzz tests, while the manual workflow had over 200 tests. With interactive steering and careful context resets, the same skills did eventually match some of the manual findings, although without the intended effect as an unattended one-shot.
The key reason for the poor skill performance is that, as the campaign progressed, working through different strategies and steps made the context unmanageable. The instructions that mattered most were soon consumed by context rot, and by the end of the execution, core directives such as preserving failing tests as evidence, keeping strict equality to avoid ignoring off-by-one errors, and never fixing production code were quickly lost in the final result.
It became clear that we needed a better strategy.
Phase 2: Autoresearch
The second attempt was an autoresearch loop: each iteration ran the whole harness against the target in a fresh worktree, was scored against a hidden evaluation set containing the manually found bugs as ground truth, and then a mutator agent rewrote the prompts and topology for the next iteration.
This again hit a wall.
The master skill would not converge: halfway through the 20-iteration limit, the loop had reproduced almost none of the original ground-truth bugs, and scores were not monotonic: an iteration would find a bug and the next would lose it, with failing reproducer files from iteration simply vanishing in iteration .
In hindsight, this was not strong evidence against autoresearch itself. Our loop was too broad, slow, and serial to get the full benefit from an optimization process that usually needs many cheap iterations.
We tried rebuilding the scoring system, but it fared no better, since prompts started to game the system to promote runs that produced many findings and theoretical "new" bugs, often with many false positives, over runs that produced a few validated ones. Since we did not have a complete ground truth, as the codebase had been unaudited, every new bug needed careful re-evaluation, and during the autoresearch experiment we did not have a robust triaging system.
Another optimization we tried was to run autoresearch on individual steps in parallel micro-loops instead of the single one-shot master skill. The idea was that we could have manageable intermediate metrics as proxies for the most important metric: number of bugs found. But it did not help either. Some skills did not have a clear hillclimb proxy, especially the ones related to initial setup stages. We believe more recent research related to skill optimization, such as SkillOpt, can still be used, provided that clear metrics and eval systems are in place.
In any case, after many attempts, autoresearch did not converge, and the experiment failed.
Nevertheless, the loop did leave us with one accidental discovery.
While debugging why it kept underperforming against the manual baseline, we re-ran the same harness multiple times, unchanged, against a fresh copy of the target. After a few attempts, the same skill produced new candidate findings: some of them valid production bugs that were not in our original list at all.
Two executions of the same prompt had produced two largely disjoint bug sets.
This made us realize that, despite the loop not having materially improved the harness, the interesting variance was coming from the model itself. Running the same prompt multiple times can find different bugs each time, mostly due to the nondeterministic nature of LLMs. This learning became another knob of the current Ultrafuzz design.
Phase 3: Workflows
We initially wanted to rely on simple skills because they would be easier for end users to incorporate. Eventually, we stopped optimizing one-shot prompts and started thinking about how to make the system look more like Bugfinder: specialized agents, helper tools, explicit instructions, and a fixed workflow.
We considered building on existing orchestration frameworks, such as libraries in Rust, Python, and TypeScript, but settled on writing our own: we needed something simple, strictly local, with minimal features that we could adapt.
We chose to develop Ultrafuzz as a single binary, with the executor, CLI, and dashboard all shipping together. For the frontend, a simple React app makes the visualization possible and extensible for users who want to change their prompts on the fly.
The design bets are extensibility and inspectability. See excerpts below.
Prompts
Prompts are Markdown. ultrafuzz init writes every campaign prompt into the target repository under .ultrafuzz/prompts/, where users can edit them or drop in new ones. For example, an encode/decode strategy prompt begins by defining the role and test objective:
---
id: encode-decode
display_name: Encode / Decode
---
You are a Fuzzing specialist for Solidity smart contracts.
Your job is to author encode/decode Foundry fuzz tests for specific flows from this project,
by understanding which functions implement encoding or decoding logic, making sure that
decode(encode(x)) == x for all targets.
Read these handoff artifacts before selecting targets:
{{artifact_handoff:base-test-setup}}
{{artifact_handoff:property-specification-fanin}}
Topology
The topology is YAML. The campaign graph lives in .ultrafuzz/topology.yml, which is useful as both machine-readable and human-readable. Adding a new strategy is just adding a Markdown file and a node to the topology:
nodes:
- id: encode-decode
prompt: strategies/encode-decode.md
group: strategies
depends_on:
- property-specification-fanin
loops: 1
loop_mode: parallel
required_artifacts: []
Config
Configuration is TOML. Runtime settings live in ultrafuzz.toml, keeping backend selection, concurrency, permissions, triage, and dashboard settings separate from graph wiring:
[run]
output_dir = ".ultrafuzz/runs"
max_parallel_agents = 4
workspace_mode = "git-worktree"
[backend]
default = "codex-cli"
[triage]
quorum = 4
panel_size = 5
Messages
Message passing uses files. Nodes hand off work through Markdown and JSON artifacts, referenced in later prompts through template variables such as {{artifact_handoff:property-specification-fanin}}. In one current run, the property fan-in node wrote .ultrafuzz/runs/<run-id>/artifacts/property-specification-fanin/properties.md, which downstream strategies consumed:
# Consolidated Property Specifications
Source key: `rv` means `runtime-verification`; other prefixes match the artifact names.
| Canonical ID | Property | Category | Priority | Source IDs |
| ------------ | --------------------------------------------------------------- | ------------------- | -------- | ---------------- |
| PROP-001 | ERC4626-like vault view functions must be caller-independent... | ERC4626 view safety | P1 High | a16z-001, rv-006 |
Workflow
The Ultrafuzz campaign moves through four phases.

Each attempt runs in a fresh context inside its own git worktree and uses a CLI backend (Codex or Claude Code), using whatever session or API key the operator already has.
Setup
Discovers the project, its actors and user flows, prepares the Foundry harness (converting from Hardhat when needed), and establishes a shared base test, deliberately designed so the same fixture can later serve the invariant suite. This follows lessons from protocols where BaseTest extends Foundry's Test and an abstract Setup contract responsible for deploying the whole infrastructure. This allows stateful invariant tests with Echidna or Medusa to inherit from Setup without extending any Foundry boilerplate.
Properties
Enumerates what system invariants should hold. This builds on a variety of open-source material from audit companies and security researchers: Certora, Trail of Bits, Runtime Verification, A16Z, and Recon. These lenses are executed independently and then deduplicated into a list of invariants.
Strategies
Authors the fuzz tests. As previously mentioned, each testing methodology is a strategy: differential tests, round-trip tests, invariant tests, and so on. The project started with 5 hardcoded strategies from the manual engagement:
- Parametric user flows: convert all actor-based workflows into fuzz tests
- Round-trip properties: understand which user actions come in pairs (deposit/withdraw, mint/redeem, buy/sell, make/take)
- Differential tests: execute the optimized version against a non-optimized version
- Property-based tests derived from pre-existing property repositories
- Stateful invariant tests: build invariant tests
This later evolved to about 20 strategies in the current version of the tool. The key jump came after a review of the first unattended CLI run, which had surfaced only a few findings. When asked how to improve recall against the known ground-truth set, the agent suggested adding more specialized strategies, which helped drive a big step up from the first to second iteration.
We expect this list to continue to grow as we extend to more protocol types and verticals. Beyond the growing number of strategies, each prompt runs with fresh context multiple times (3 attempts by default, configurable) in isolated worktrees, as we learned from our autoresearch quest. Model profiles can additionally fan the same strategy across backends and models, which also lets us trace which model wrote the test that caught which bug. More often than not, a bug can be traced to only 1 out of 3 executions, which shows that this number should perhaps be increased for higher-confidence runs.
Review
Deduplicates, adjudicates, and reports findings. We put a lot of focus on precision, so every issue goes through a committee of independent evaluators (five judges by default) to classify its validity, and a supermajority determines whether it goes into the report or not.
Evaluation
Iteration Comparison
After the first campaigns, we deliberately rewrote every strategy to be generic, stripping out anything specific to the benchmark target, because an overfit strategy would never transfer to the next target.
We define the recall denominator as all valid issues, including both clear production issues and findings that depend on underspecified behavior or explicit assumptions. These issues are assigned Low severity by default because they may be disputed based on the protocol's intended behavior, and typically reflect gaps in the documentation or whitepaper. This is the classic type of Low severity issue that can escalate into a Critical vulnerability when combined with other findings. Such exploit chains are often difficult to demonstrate without hindsight and extensive analysis. For this reason, we encourage developers not to dismiss reachable but unproven attack paths, and to address seemingly minor issues before they can contribute to unexpected production failures.
Excluding findings related to incomplete specifications would make the metrics appear cleaner, but it would also obscure whether the campaign identified ambiguous yet actionable gaps that still require engineering decisions. The final denominator is therefore 27 findings: 22 clear production issues and 5 underspecified findings. The severity split is 2 High, 15 Medium, and 10 Low. False positives in this evaluation were harness defects: failures caused by generated tests rather than production behavior.
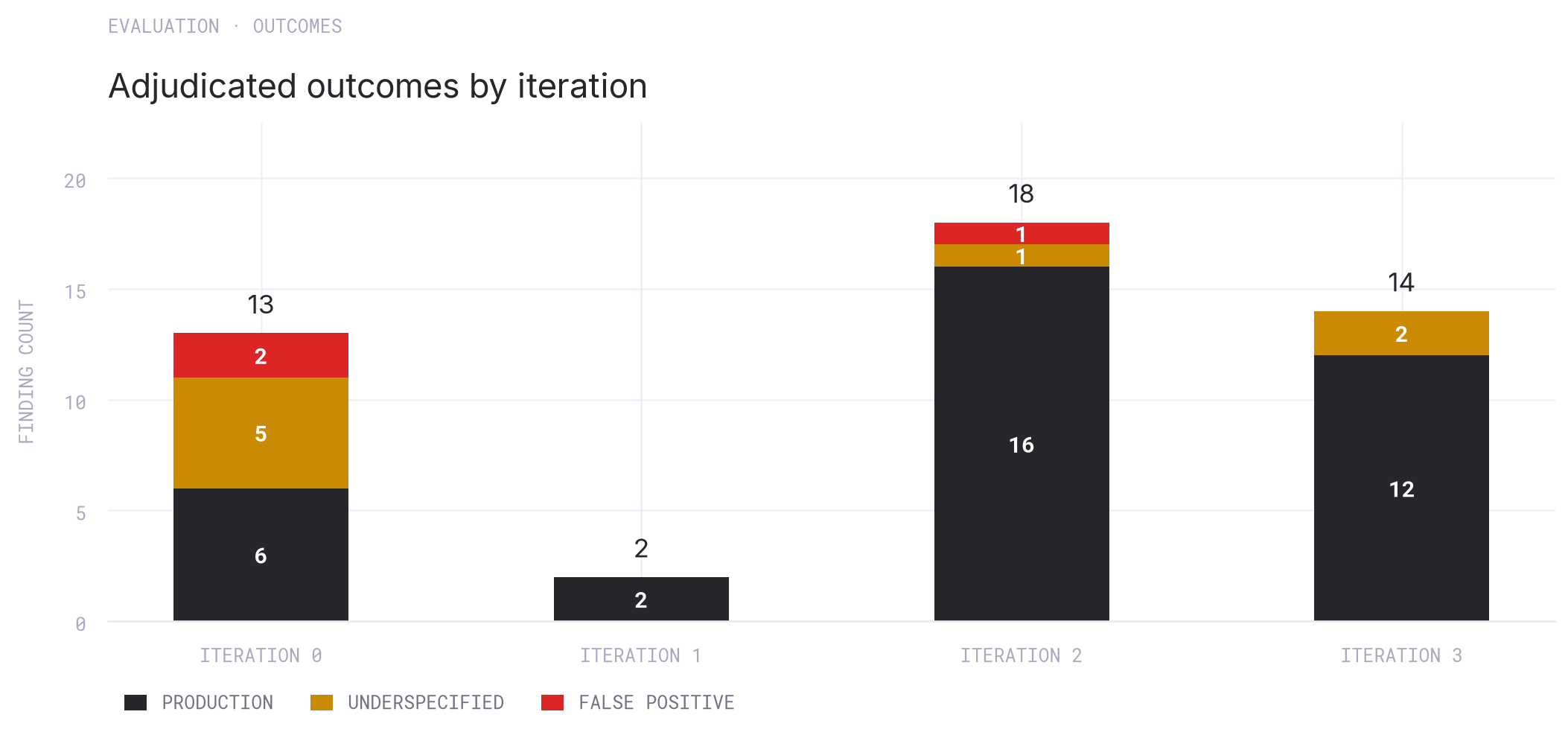
Adjudicated top-level outcomes by campaign iteration.
For this evaluation, a production issue is a validated defect in production code or behavior. An underspecified issue is a valid finding whose exploitability or expected outcome depends on missing specification detail, an explicit assumption, or a policy decision. A false positive is a reported failure caused by the generated test harness rather than production behavior. A top-level count covers issues surfaced in the final report list rather than supporting artifacts.
Iteration 0 was the manual, pre-CLI baseline. Iteration 1 was the first unattended CLI run and found only 2 valid top-level findings. Iteration 2 materially improved because the campaign graph widened: more specialized strategies consumed the shared property catalog, most strategy families were run more than once, the run generated many more test files, and the final report no longer showed the artifact handoff failures that limited the first CLI run. It found 17 valid top-level findings plus one false positive. Iteration 3 used a similar expanded shape with still more repetition and review, found 14 valid top-level findings, and added several root causes that earlier runs missed, while also missing some findings from Iteration 2.
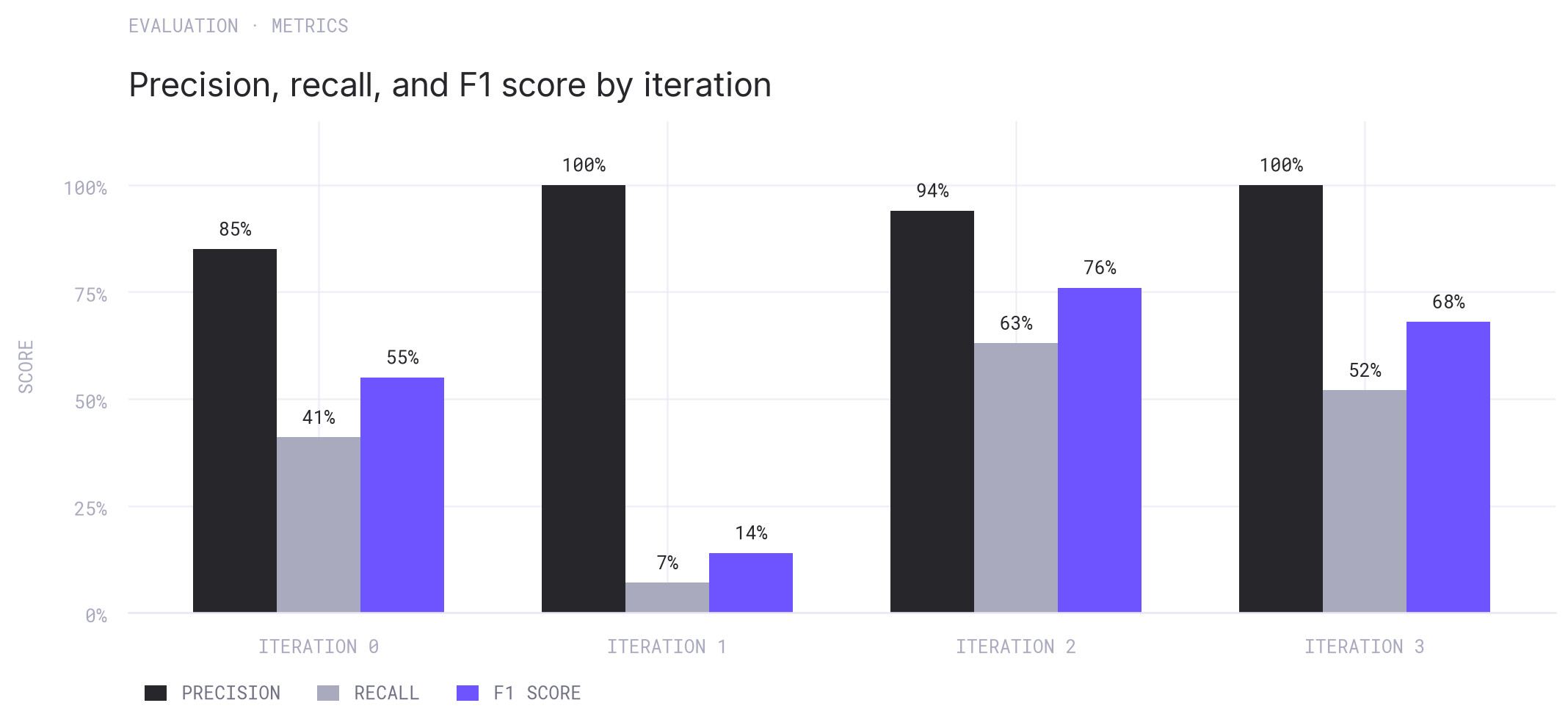
Evaluation metrics by iteration using all tracked findings.
Intersections matter because repeated campaigns find overlapping but non-identical issue sets. A higher single-run count is useful, but reliability depends on whether a later run rediscovers earlier failures or only samples a different slice of the space; the overlap chart separates shared discoveries from one-off discoveries across iterations.
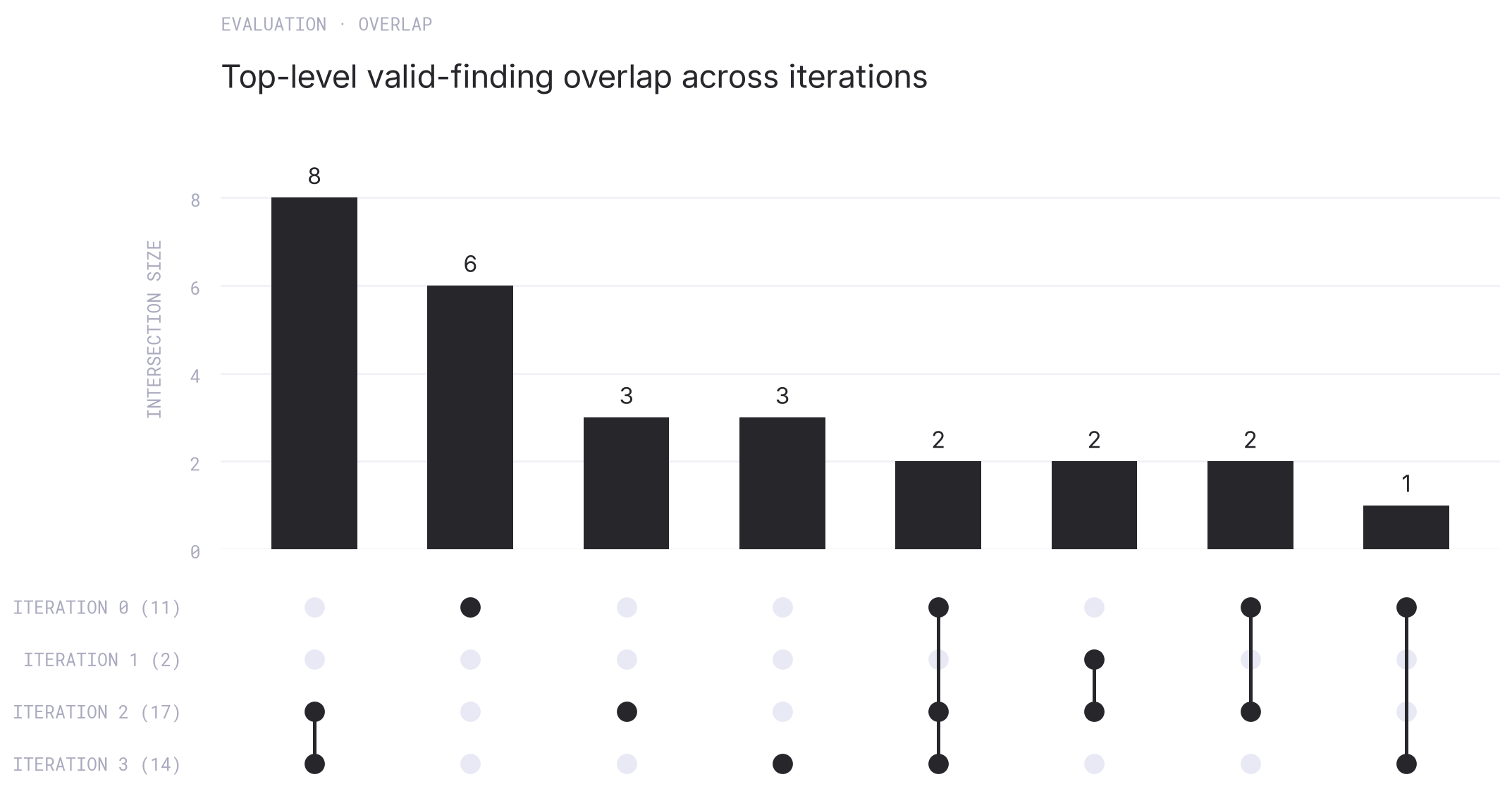
Top-level valid-finding overlap across iterations, shown as an UpSet figure.
Seen cumulatively, the runs look closer to pass@k than to a single-run benchmark: the unique valid-finding count rises from 11 to 27 after three iterations, with the last iteration still adding three new roots after most of the easy overlap had already been exhausted. It is still possible that more iterations would keep surfacing production bugs, so users are encouraged to keep running the tool in a loop until subsequent runs surface no new findings.
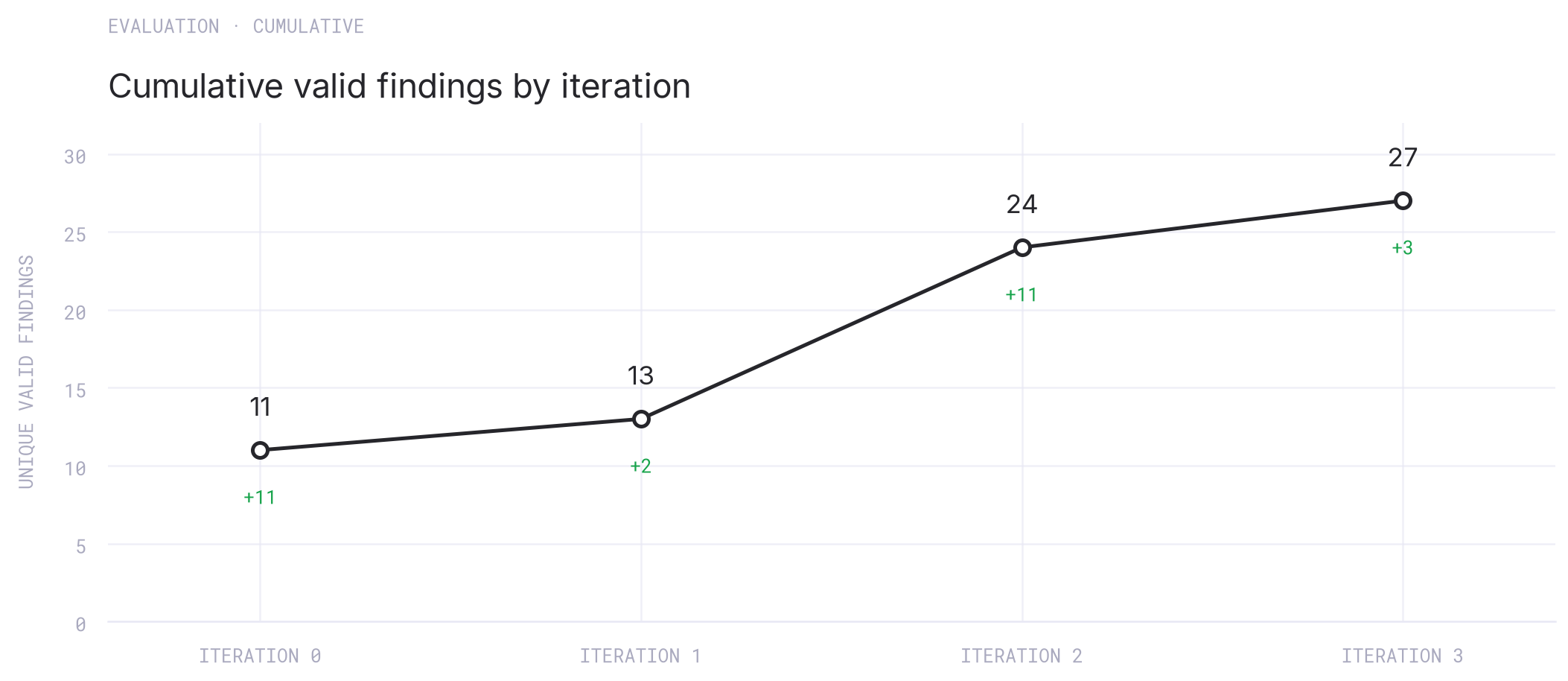
Cumulative top-level valid findings by iteration.
The remaining misses still taught us something important: for every known issue that the last iterations missed, we already had the relevant strategy, but the strategies lost protocol-specific context as we generalized them to avoid overfitting. Key concepts, entity names, and specific details that we had emphasized during the manual workflow were removed. By making the strategies too broad, they failed to reach the target-specific paths that the tailored manual workflow had been nudged toward. A key learning is that each distinct protocol run should be manually extended to address its protocol-specific details. More generally, that manual pass can be incorporated into dynamic workflows adapted from initial learnings in the research, discovery, or threat-modeling phase.
AI Tools Comparison
We also compared the aggregated Ultrafuzz report against four AI audit tools. Each external report was evaluated by five adjudicators using the same triage criteria. The external tools are presented below as Tool 1 through Tool 4. The first two are open-source solutions, while the latter two are commercial paid services.
For recall, we did not freeze the denominator at the original 27 findings. The external reports surfaced 11 distinct novel findings, making the denominator 38 counted issues: 27 known valid findings plus 11 confirmed external findings that Ultrafuzz did not report. That lowers Ultrafuzz recall to 27/38, or 71.1%.
Counted true positives means known ground-truth matches plus unique confirmed external findings. The chart below summarizes precision, recall, and F1 across Ultrafuzz and the four AI-tool baselines. One tool did not produce any validated true positives after adjudication, as all reports were either false positives or informational recommendations.
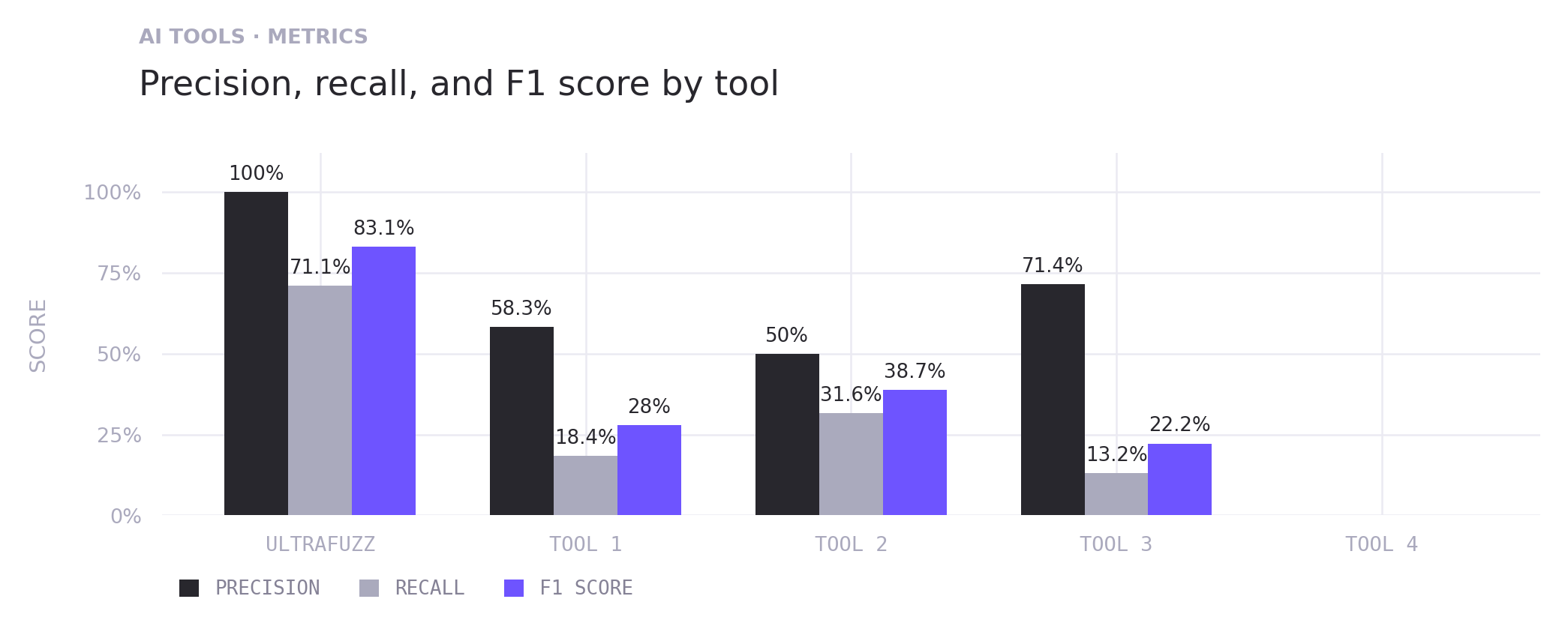
Precision, recall, and F1 score across Ultrafuzz and the four AI-tool baselines.
Costs
A full campaign running with gpt-5.5 at xhigh reasoning effort costs about $150 in API credits at two attempts per strategy, and an estimated $230 at 3 attempts per strategy. Wall-clock time ranged from roughly 4 hours at two attempts to 6 hours at three. Both are a fraction of the cost and calendar time of the equivalent manual engagement, which shows the benefit of running these automated tools as another pre-audit step before a manual review.
Next steps
Beta testing
We are currently working with Monad ecosystem teams to run Ultrafuzz against their protocols, and campaigns are already running beyond the original benchmark target. We invite all Monad builders to reach out and put their codebase to the test.
Expanding on strategies
Because strategies are plain Markdown prompts, any fuzzing specialist can encode their methodology as a strategy and ship it. We expect the catalog to grow the same way the property lenses did.
Dynamic strategies
The overfitting lesson points to the next architectural step: a campaign stage that writes target-specific strategies from the protocol's own documentation and threat model, including what is out of scope, which trust assumptions hold, and which integrations are assumed correct, on top of the generic catalog.
Further benchmarks
We intend to extend our evaluation framework to include other protocol types and conduct ablation studies to understand which knobs have the highest leverage on the final result.
Open sourcing
We plan to open source Ultrafuzz after the initial testing phase with Monad ecosystem projects, once the codebase has been polished and the tool has gone through internal security review.
If you would like to try or contribute to Ultrafuzz, please reach out. We would love to add property-specification frameworks and strategies that cover as many useful cases as possible.